

























dr inż. Sławomir Maćkowiak
Katedra Telekomunikacji Multimedialnej i Mikroelektroniki, Politechnika Poznańska
W handlu detalicznym dokonuje się obecnie transformacja z tradycyjnego podejścia opartego na „sklepie z cegły” do coraz to nowszych rozwiązań wykorzystujących nowoczesne platformy technologiczne, np. internetowe witryny z funkcjami e-commerce.
Jednocześnie na rynku pozostaje wielu tradycyjnych sprzedawców detalicznych, którzy wobec dużej konkurencji zostali zmuszeni do przeanalizowania swoich strategicznych priorytetów, zrewidowania docelowego klienta, dokonania konwergencji kanałów handlowych i komunikacyjnych oraz określenia nowego podejścia marketingowego oraz merchandisingowego.
Tradycyjne sposoby pomiaru efektywności i aktywności sklepu nie zapewniają dobrej empirycznej oceny ani wiedzy na temat optymalizacji i skuteczności prowadzonych działań. Wraz z intensyfikacją konkurencji w celu przyciągnięcia klientów oraz zwiększenia marży zysku i sprzedaży inwestowanie w technologie dostarczające detalistom przewagę konkurencyjną stało się już koniecznością.
Jednym ze sposobów wykorzystania istniejących systemów zarządzania treścią wizyjną (VMS) i wyodrębniania danych dla wszystkich operacji detalicznych jest dostępność wysokiej mocy platform komputerowych wraz z zaawansowanymi algorytmami analizy zawartości obrazu. Wykorzystując istniejącą infrastrukturę systemów dozoru wizyjnego platformy analizy treści wizyjnych i platformy analityki biznesowej, tj. przekształcania danych w informacje, a informacji w wiedzę, która może być wykorzystana do zwiększenia konkurencyjności przedsiębiorstwa, detaliści mogą śledzić i analizować ruch klientów, monitorować i zarządzać personelem, a także zapewnić skuteczne umieszczanie produktów i planować układ sklepu.
Rozwiązania te, oprócz tradycyjnych technologii punktów sprzedaży (POS) i zliczania osób, umożliwiają też określenie dokładnych i holistycznych danych o wzorcach zachowań klientów. Szczegółowe informacje uzyskiwane z zaawansowanych inteligentnych narzędzi biznesowych ułatwiają sprzedawcom podejmowanie bardziej świadomych decyzji w celu poprawy marketingu, zwiększenia efektywności operacyjnej i sprzedaży, podniesienia poziomu zadowolenia klientów i poprawy ogólnego doświadczenia zakupowego.
Większość detalistów modernizuje istniejące infrastruktury systemów dozoru wizyjnego w taki sposób, aby móc korzystać z zalet technologii opartych na protokole IP. Technologia ta w połączeniu z zintegrowanym pakietem rozwiązań do analizy obrazu pozwala w prosty sposób uzyskać wiele dodatkowych informacji, które mogą przełożyć się na wynik biznesowy działalności. Należy się zatem przyjrzeć, jak zaawansowana inteligentna analiza treści wizyjnych może pomóc zwiększyć efektywność w handlu detalicznym.
Mapy ciepła
Jedną z podstawowych technik analizy w handlu, wykorzystującą informacje z systemów kamer, są mapy (Heat Map – w dosłownym tłumaczeniu mapy ciepła). Mapy ciepła przedstawiają wyniki analizy zachowania kupujących w sklepie w określonym czasie. Dla sprzedawców istotne z punktu widzenia efektywności sklepu są dwie informacje: którędy kupujący poruszają się, będąc w sklepie, oraz które towary najczęściej oglądają. Poprzez sprawdzanie liczby osób, przeanalizowanie wzorców ruchu w sklepach, analizy gorących punktów i czasu przebywania wokół określonych produktów i w określonych obszarach sprzedawcy detaliczni mogą wyodrębnić strefy kluczowe najchętniej odwiedzane przez klientów oraz te o mniejszym natężeniu ruchu.
Uzyskane informacje można wykorzystywać do lepszego projektowania powierzchni sklepowej, rozmieszczania produktów czy też określania metod promocji. Jeśli np. określony dział jest rzadko odwiedzany, układ sklepu można zmodyfikować w taki sposób, aby pomóc klientom do niego dotrzeć, ewentualnie wprowadzając układ jednokierunkowy alejek między działami, wymusić na klientach przejście przez dany dział.
Druga grupa map prezentuje wyniki analiz popularności towaru. Określenie poziomu popularności danego produktu może być powiązane np. z częstotliwością dotykania danego produktu, a więc z zachowaniem się klienta w sklepie. Większe zainteresowanie daną rzeczą przez kupujących oznacza większą szansę na jej sprzedaż, stąd też zebrane dane pozwalają wyodrębnić preferowane modele czy kolory. Mapy, w kolejnym etapie, pomagają także zidentyfikować problem cen, ponieważ duża popularność towaru, nieidąca w parze z jego kupnem, może oznaczać zbyt wygórowany koszt stanowiący przyczynę rezygnacji z zakupu.
Jak zatem są budowane mapy ciepła i jak się określa zachowanie klienta w sklepie?
Na podstawie obrazu z kamer IP dokonuje się detekcji obiektu, a następnie śledzi dany obiekt w scenie oraz między widokami rejestrowanymi przez pozostałe kamery. W celu określenia dobrej mapy cała powierzchnia sklepu powinna zostać objęta dozorem wizyjnym, gdyż dokładne śledzenie ruchomych obiektów w sekwencjach wizyjnych ma istotne znaczenie ze względu na prawidłowość odwzorowania trajektorii ruchu obiektu w topologii całego obszaru sklepu. Wyróżnia się dwa rodzaje map ze względu na sposób ich konstruowania. Pierwszy, klasyczny typ map opiera się na agregacji danych o ruchu obiektów na podstawie danych z pojedynczej kamery. Przy konstruowaniu tego typu map wykorzystuje się klasyczne metody detekcji i śledzenia obiektów, które pozwalają wyznaczyć trajektorię zmian położenia obiektu w obrazie, a następnie trajektoria ta jest rzutowana na powierzchnię reprezentującą topologię sklepu. Każda kolejna informacja o trajektorii ruchu dla kolejnego obiektu jest agregowana łącznie na mapie topologii sklepu, co pozwala wizualizować skumulowany wynik położenia tych trajektorii (rys. 1).
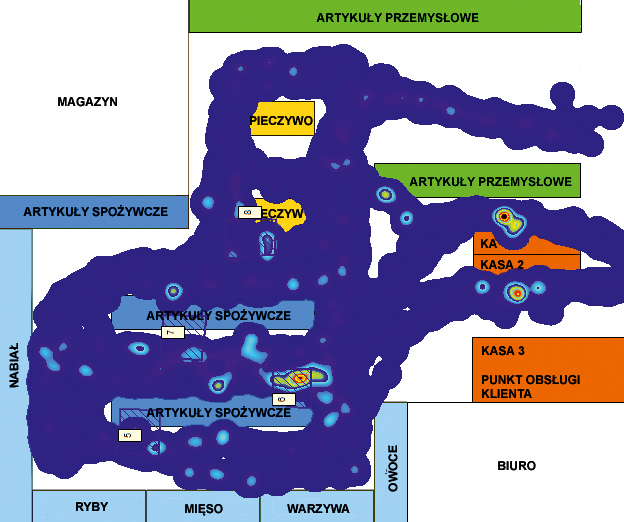
Wizualizacja liczby zjawisk jest reprezentowana odpowiednim kolorem. Miejsca o wyższej wartości danego zjawiska są oznaczane kolorem czerwonym, a wraz ze spadkiem jego natężenia przechodzą poprzez kolory żółty, zielony, aż do niebieskiego. Pozwala to na łatwą interpretację wyniku. Rzutowanie trajektorii odbywa się niezależnie dla każdej z pozostałych kamer umieszczonych w sklepie. Taka mapa ma podstawową wadę – za jej pomocą nie można przeanalizować dokładnej ścieżki poruszania się obiektu w całym sklepie i przypisać danemu obiektowi różnych zachowań, które były z nim związane. Drugi typ map jest znacznie trudniejszy w konstrukcji, ale nie ma wymienionej wady. Przy konstrukcji tej mapy stosuje się mechanizmy śledzenia obiektów między kamerami. Przyjrzyjmy się dokładniej, jakie techniki można obecnie wykorzystać.
Reidentyfikacja obiektów
Jedną z technik wspierających śledzenie obiektów w systemach wielokamerowych w dużej przestrzeni, przy wielu śledzonych obiektach, jest reidentyfikacja obiektów. Pojęcie reidentyfikacji często bywa mylone lub jest używane zamiennie z identyfikacją. Pomimo podobieństwa występującego nawet w algorytmach wykorzystywanych w obu tych zadaniach reidentyfikacja i identyfikacja to dwa procesy o odmiennych celach. Zadaniem identyfikacji jest jednoznaczne odwzorowanie pewnych cech charakterystycznych w dane identyfikacyjne, wcześniej wprowadzone do systemu.
Z kolei reidentyfikacja polega na dynamicznym tworzeniu bazy obserwowanych obiektów w celu określenia, czy obiekt właśnie widoczny w obiektywie kamery został wcześniej zarejestrowany. W przypadku reidentyfikacji nie są gromadzone żadne dane osobowe, jak to ma miejsce w przypadku identyfikacji. Istotne jest również to, że dane w bazie są przechowywane tylko przez określony czas, po którym są usuwane. Może to być np. czas od wejścia klienta do sklepu aż do jego wyjścia z niego.
Reidentyfikacja może być stosowana w celu tworzenia danych statystycznych dotyczących sposobu i kierunku przemieszczania się osób w monitorowanym obszarze. Tego rodzaju informacje można wykorzystać np. do usprawniania komunikacji lub oceny przepływności osób w centrach handlowych. W przypadku śledzenia i reidentyfikacji uzyskiwane informacje są bardziej szczegółowe niż te pozyskane z badania przepływności w obrazie. Jedną z zasadniczych wad klasycznych modeli ruchu jest utrata wielu szczegółowych informacji o sposobie realizacji poszczególnych przemieszczeń na skutek agregacji do poziomu podróży. W związku z tym w modelowaniu potoków ruchu coraz częściej stosuje się modele oparte na aktywnościach, w których uwzględnia się zależności pomiędzy pojedynczymi łańcuchami przemieszczeń realizowanymi przez poszczególne osoby.
Dotychczas analizy dotyczące potoków przemieszczania się osób opisywały charakterystyki ilościowe, takie jak jego czas i równomierność, struktura i rozmiar, pozwalając budować model generowania ruchu czy też model rozkładu przestrzennego ruchu w postaci dość ogólnej.
Analizując informacje o aktywności użytkowników (użytkownikiem można nazwać pojedynczy przemieszczający się obiekt) od momentu rozpoczęcia przemieszczania do jego miejsca docelowego, wykorzystywanych narzędzi pomocniczych, np. wózka, koszyka i drogi przemieszczania się, można określić parametry potoków, tzn. w ich opisie uwzględnić informacje o węźle początkowym i docelowym, a także zapotrzebowanie na określoną przestrzeń pomiędzy tymi węzłami, dokonując tym samym optymalizacji ze względu na czas i pojemność danej alejki.
Można zatem dokonać segmentacji i opisać cechami charakterystycznymi potok obiektów między węzłami, tworząc dokładny model ruchu, a w późniejszym czasie wykorzystać go do lepszego zaprojektowania powierzchni sklepowej. Reidentyfikacja pozwala na efektywne śledzenie obiektów w wielokamerowych systemach dozorowych, bez konieczności stosowania nadmiarowej liczby kamer.
Wykorzystując informacje o pozycji kamer w obserwowanej przestrzeni oraz algorytmy predykcji miejsca i czasu pojawienia się obiektu, można zwiększyć skuteczność reidentyfikacji.
Inne mechanizmy wspierające obecnie techniki śledzenia
Największym wyzwaniem, które zostało zidentyfikowane podczas analiz, jest problem częstego przesłaniania się obiektów. Z punktu widzenia zastosowania metod znanych z analizy obrazów (których akwizycja jest przeprowadzana wyłącznie z jednej kamery) jest to problem nadal nierozwiązany. Nowoczesne techniki śledzenia obiektów muszą umiejętnie poradzić sobie z rozróżnieniem cech obiektów biorących udział w przesłanianiu, gdy takie zdarzenie ma miejsce. W rzeczywistych sytuacjach ma się do czynienia z trzema typami przesłaniania obiektów: przesłanianie samoistne obiektu, gdy część obiektu przesłania inną część tego samego obiektu, przesłanianie między obiektami, gdy jeden z obiektów jest przesłaniany przez inny, oraz gdy struktura tła lub obiektu przesłania inny obiekt/obiekty.
• Model wokselowy obiektu
Jedną z ciekawszych, bardzo skutecznych technik śledzenia jest metoda śledzenia wysegmentowanego obiektu metodą modelu wokselowego (woksel to najmniejszy element przestrzeni w grafice 3D, volumetric picture element) w przestrzeni trójwymiarowej. Podstawową zaletą modelu wokselowego jest jego główna cecha, czyli wysegmentowana skutecznie przestrzeń sceny. Każdy z obiektów, mimo przesłaniania się w widokach, ma jednoznacznie ograniczoną objętość, którą można rzutować na płaszczyznę podłoża. Nie ma zatem problemów z rozróżnieniem obiektów – każdy ma numer indywidualny, który do momentu wyjścia obiektu ze sceny z wszystkich widoków jest prawidłowo utrzymywany przez zarządzający obiektami mechanizm śledzenia.
Wysegmentowana scena za pomocą modelu wokselowego o wiele lepiej skutkuje prawidłowym przypisaniem identyfikatora danemu obiektowi, niż ma to miejsce w przypadku przekształceń macierzy homograficznych i klasycznych metodach detekcji obszaru poruszającego się i jego klasyfikacji. Na błąd położenia w takich systemach istotny wpływ ma wynik klasyfikacji i rozróżnienia (rozdzielenia) obiektów. Model wokselowy obiektu może być także efektywnie wykorzystany w analizie zachowań obiektów.
• Mapy głębi
Kolejną techniką wspierającą mechanizmy śledzenia, radzącą sobie bardzo dobrze z drugim typem przesłaniania (gdy obiekty przesłaniają się między sobą), jest technika wykorzystująca informacje zawarte w mapach głębi. Ten typ analizy wymaga jednak informacji o głębi sceny, którą można uzyskać, np. stosując pary kamer lub kamery z sensorem głębi.
Moduł śledzenia składa się z dwóch równolegle pracujących pętli. Pierwsza pętla pracuje na kolejnych w czasie widokach, standardowych obrazach. Jest to typowa implementacja systemu detekcji i śledzenia oparta na segmentacji i klasyfikacji obszarów poruszających się w scenie. Ta część rozwiązania jest znana z literatury.
Proces detekcji ruchu określa położenie obszarów przypisanych obiektowi (obszar jednolity reprezentujący poruszające się punkty obrazu o podobnych właściwościach związanych z ruchem) i tworzy listę kandydatów obserwacji aktualnych aktywnych obszarów w scenie. W większości systemów obszary te są wyznaczane poprzez odjęcie zamodelowanego tła reprezentującego statyczne tło (widok referencyjny) od widoku aktualnego. Zazwyczaj taki obszar jest reprezentowany przez okalający prostokąt, przyległy do najbliżej granicy obszaru. Moduł śledzący jest zaimplementowany jako dwukrokowe podejście: predykcja i korekcja. W etapie predykcji śledzona pozycja obiektów z poprzedniej ramki jest rzutowana na aktualną ramkę odpowiednio do trajektorii wyznaczonej przez model. Następnie w etapie asocjacji danych przewidywane pozycje obiektów są konfrontowane z listą kandydatów obserwacji, tj. obiektów z fazy detekcji obiektów. Odpowiadające sobie pary – obiekt i obserwacja z detekcji – są łączone.
Zastosowanie drugiej pętli jest nowym proponowanym rozwiązaniem w systemach śledzenia osób. Pętla ta działa na dwuwymiarowym histogramie mapy głębi. W tej przestrzeni proces wyznacza poruszające się obszary i tworzy listę kandydatów obserwacji obiektów. Algorytm wyznacza obszary reprezentujące poruszające się obiekty w dwuwymiarowej przestrzeni histogramu.
Jeśli dwa lub więcej obiektów przesłania się między sobą, wciąż możliwe jest rozdzielenie tych obiektów w dwuwymiarowym histogramie mapy głębi. Jedynym wymaganiem jest, aby obiekty miały przypisaną różną głębię. Gdy ten warunek jest spełniony, obiekty w przestrzeni dwuwymiarowego histogramu mogą być reprezentowane jako oddzielne obszary. Segmentacja obiektów w przypadku przesłaniania jest tym samym znacznie łatwiejsza.
• Zastosowanie obiektywu z dystorsją beczkową
Bardzo ciekawym rozwiązaniem w śledzeniu obiektów jest możliwość wykorzystania zniekształcenia beczkowego do uzyskania efektu płynnej zmiany ogniskowej w obiektywach stałoogniskowych o szerokim kącie widzenia. System taki pozwala na rejestrację szerokiego pola widzenia przy jednoczesnej możliwości uzyskania przybliżenia obiektu znajdującego się w środku sceny.
Proponowane rozwiązanie wspiera algorytmy śledzenia obiektów, gdyż system, udostępniając jednocześnie obrazy o szerokim i wąskim kącie widzenia, zapobiega sytuacji utraty obiektu w rejestrowanym obrazie przy gwałtownym jego ruchu.
Przykładowo, stosując przetwornik obrazu o małej rozdzielczości matrycy np. 1 Mpix oraz obiektyw z silną dystorsją beczkową, można uzyskać jednocześnie (wykorzystując odpowiednią funkcję) obraz o szerokim kącie widzenia np. 160° oraz wycinek ze środka (zoom) przetwornika o wąskim kącie np. 40° i rozdzielczości np. 184 x 184 piksele. Aby uzyskać tę samą rozdzielczość wycinka obrazu (w tym przypadku 184 x 184) z obiektywu bez dystorsji i o tym samym całkowitym kącie widzenia (160°), trzeba by użyć przetwornika o około 16 razy większej rozdzielczości, tzn. 16 Mpix. Oznacza to także, że nie uzyska się tak dużej prędkości ramkowej jak z matrycy 1 Mpix. A należy pamiętać, iż duża prędkość ramkowa jest zaletą w przypadku algorytmów automatycznej detekcji czy też śledzenia obiektów. Zatem proponowane rozwiązanie można wykorzystać do budowy systemu pozwalającego na płynną zmianę ogniskowej przy obiektywie stałoogniskowym (tzw. rybie oko).
Ciekawszym rozwiązaniem wydaje się jednak zastosowanie prezentowanej idei w systemach automatycznego śledzenia i identyfikacji obiektów, gdyż umożliwia ono uzyskanie, na podstawie jednego obrazu wejściowego, równocześnie kilku obrazów o różnym kącie widzenia i podobnej rozdzielczości. W efekcie możliwe są jednoczesna analiza i śledzenie obiektu na kilku płaszczyznach obrazowych, a więc trudniej zgubić obiekt, który jest na obrazie o największym powiększeniu, gdyż cały czas może być także śledzony na płaszczyznach o szerszym kącie widzenia.
Jak rozpoznawać aktywność obiektów?
Przedstawię dwa kierunki rozwoju takich technik. Pierwszy oparty na cechach charakterystycznych obiektów wyznaczanych na wysegmentowanym konturze obiektu oraz drugi wykorzystujący do opisu zbiór cech wyznaczonych dla całego obszaru reprezentującego obiekt.
• W pierwszej grupie rozwiązań modelowanie aktywności osób na podstawie sekwencji wizyjnych rejestrowanych z wykorzystaniem jednego widoku można realizować przy użyciu wielu różnych technik, m.in. poprzez modele oparte na grafach prawdopodobieństwa, np. sieci Bayesa, sieci propagacji, modele semantyczne czy podejścia syntaktyczne lub regułowe.
Wykorzystanie grafów do modelowania aktywności obiektów jest stosowane z dobrymi efektami do modelowania przede wszystkim złożonych zachowań osób i opisu ich aktywności w zatłoczonych miejscach publicznych. Rozwiązanie to pozwala na wykorzystanie w procesie detekcji punktów charakterystycznych leżących na konturze sylwetki człowieka.
Zachowanie może być opisane jako zbiór trajektorii przemieszczania się punktów charakterystycznych podczas wykonywania danej czynności. Zbiór punktów charakterystycznych w danej chwili definiuje pozę. Zbiór póz zdefiniowanych dla kolejnych punktów czasu tworzy deskryptor. Zbiór punktów definiujący pozę może mieć różną konfigurację dla różnych typów wykrywanego zachowania. Dla kolejnych ramek obrazu pozycje punktów należących do zbioru są śledzone i tworzą trajektorię punktów. Następnie trajektorie są porównywane – poprzez obliczenie odległości dla par odpowiadających sobie punktów – z predefiniowanymi trajektoriami odpowiadającymi danemu zachowaniu. Każda trajektoria musi mieścić się w określonym z góry przedziale.
Kluczowym zagadnieniem w tej grupie rozwiązań jest dobra segmentacja obiektu. Dopiero wówczas, na podstawie uzyskanych modeli można podjąć próbę rozpoznawania czynności (lub zachowań) wykonywanych przez osoby rejestrowane w scenie. Automatyczna segmentacja obiektu na podstawie jednego widoku, sekwencji obrazów z jednej kamery jest bardzo trudnym zadaniem. Dla sekwencji wizyjnych, których akwizycji dokonuje się za pomocą kamer okalających scenę bez jednoznacznego sposobu ich rozstawienia (a takie często występują w systemach dozorowych), można zastosować technikę segmentacji obiektów z wykorzystaniem modelu wokselowego.
Zastosowanie modelu wokselowego w przypadku segmentacji sekwencji trójwymiarowych jest uzasadnione, gdyż jest on najczęściej stosowany do reprezentacji „objętości”. Segmentacja obrazu na podstawie wyłącznie pojedynczego widoku, który jest obrazem płaskim, często prowadzi do błędnych wyników. Jest to skutek wielu czynników: różnorodnego oświetlenia sceny, podobieństwa obiektów, niemożliwości wyznaczenia innych istotnych cech obiektu, np. parametrów ruchu obiektu.
Nierównoległe ustawienie kamer, często krzyżujące się osie optyczne, również ustawienie kamer na nierównych wysokościach – wszystko to uniemożliwia skuteczne wyznaczanie map głębi. Ustawienie takie jest jednak często spotykane w przypadku systemów dozoru wizyjnego, w których różne fragmenty sceny są obserwowane przez różne kamery.
Niezależna segmentacja obiektów w widokach, przy wykorzystaniu klasycznych technik znanych z literatury, też jest nieskuteczna, ponieważ nie dostarcza informacji o powiązaniu obiektów w widokach. Z tego względu słuszne jest wykorzystanie techniki modelowania wokselowego do segmentacji obiektów.
Modelowanie sceny, obiektów będących w scenie z wykorzystaniem tworzonego w trakcie obserwacji dynamicznie zmieniającego się modelu, odzwierciedlającego rzeczywisty kształt obiektu, istotnie poprawia prawidłowość segmentacji. Obiekt modelowany wokselami jest tym dokładniejszy, im więcej informacji (więcej widoków) bierze się pod uwagę podczas jego tworzenia. Mając rzeczywisty kształt obiektów poruszających się w scenie, uzyskując wiedzę z procesu kalibracji systemu o położeniu kamer, można dokonać odpowiednich transformacji położenia modelu wokselowego w scenie i rzutowania go na odpowiednią płaszczyznę.
Technika ta daje znaczącą przewagę nad znanymi metodami segmentacji, ponieważ stworzony obiekt za pomocą modelu wokselowego stanowi powiązanie treści wszystkich prezentowanych widoków. Model jest zatem informacją, którą można wykorzystać przede wszystkim do segmentacji obiektu w wielu widokach, a także do dalszej analizy, np. zachowania się obiektu. Równocześnie największą zaletą zastosowania proponowanej techniki jest możliwość prawidłowego rozdzielenia obiektów w przestrzeni, czego nie można w łatwy sposób dokonać metodami klasycznymi.
• Drugą grupę rozwiązań rozpoznawania aktywności obiektów stanowią techniki wykorzystujące lokalne cechy charakterystyczne wyznaczane dla całego obszaru reprezentującego obiekt. Większość tego typu rozwiązań polega na wyodrębnieniu punktów charakterystycznych dla danego obiektu, a następnie ich opisaniu w zwięzłej formie za pomocą indywidualnych wektorów.
W celu wykrycia podobnych obszarów (podobnych obiektów) pomiędzy dwoma obrazami należy porównać zbiory wyznaczonych wektorów i wybrać te wektory, które najmniej różnią się między sobą ze względu na postawione kryterium. Jest to kluczowe w przypadku porównywania sekwencji zbiorów obrazów w analizie aktywności. Obszary identyfikowane przez najmniej różniące się wektory cech są obszarami najbardziej do siebie podobnymi.
Do opisu punktów charakteryzujących obraz służą deskryptory – wielowymiarowe wektory danych. Ich postać zależy od otoczenia badanego punktu. Dla jednego obrazu tworzy się od kilkuset do kilku tysięcy tego typu opisów. Stosując techniki korelacyjne, można porównać wektory otrzymane z różnych obrazów. Elementy, które charakteryzują się dużym podobieństwem, są łączone w pary. Zestawienia te wskazują na podobne obiekty znajdujące się na różnych obrazach.
Trudno wyróżnić jeden algorytm znajdujący zastosowanie we wszystkich dziedzinach, część z nich jest bowiem wyspecjalizowana do szczegółowej analizy obiektów. Ważnym czynnikiem podczas wyboru odpowiedniej metody jest czas potrzebny do analizy jednego obrazu. W celu zminimalizowania czasu pracy programu niejednokrotnie należy zaakceptować pewne niedokładności i błędy pojawiające się podczas detekcji obiektów. Ponadto wraz ze wzrostem rozmiarów rejestrowanych danych multimedialnych zwiększa się także liczba punktów obrazów poddanych analizie w jednostce czasu. Ma to bezpośredni wpływ na wydłużenie czasu wykonywania algorytmu.
Cechy charakterystyczne w obrazie można wyznaczyć znanymi metodami SIFT, SURF czy ORB. Technika SIFT (ang. Scale-invariant feature transform) jest jedną z metod wyznaczających punkty charakterystyczne obrazu oraz ich deskryptory. Algorytm ten wyznacza kluczowe punkty, które są niewrażliwe na zmianę skali obrazu, rotację, zmianę jasności obrazu, zniekształcenia. Jego idea opiera się na wykorzystaniu obrazu w kilku skalach (rozmiarach) oraz laplasjanu filtru Gaussa (Laplacian of Gaussian – LoG). Alternatywą jest metoda SURF. Zastosowanie kilku nowości zwiększyło jej skuteczność działania oraz zmniejszyło złożoność obliczeniową algorytmu.
Z kolei metoda ORB została opracowana w celu umożliwienia analizy obrazu w czasie rzeczywistym. Jej algorytm jest znacznie mniej złożony obliczeniowo w stosunku do poprzedników, co znacznie wpływa na szybkość przetwarzania. Metoda ORB może być stosowana w aplikacjach przeznaczonych do urządzeń małej mocy, działa też niezależnie od skali obrazu, rotacji, zaszumienia i zniekształcenia. Składa się ona z dwóch różnych metod: metody detekcji punktów FAST (Features from Accelerated Segment Test) oraz metody wyznaczenia deskryptora BRIEF (Binary Robust Independent Elementary Features). Zastosowanie pewnej modyfikacji tych metod umożliwiło ich wspólne i szybkie działanie.
Nowe narzędzia, nowe standardy – deskryptory CDVS
Rozwój technologii w dzisiejszych czasach wymusza jednak tworzenie nowych, bardziej zaawansowanych algorytmów, możliwych do zaimplementowania na obecnym sprzęcie. Grupa MPEG (Moving Picture Experts Group) w styczniu 2010 r. rozpoczęła pracę nad nowym standardem umożliwiającym wyznaczenie punktów lokalnych i ich deskryptorów oraz zapisanie uzyskanych danych w unormowany sposób. Narzędzie to nazywa się CDVS (Compact Descriptors for Visual Search) i zostało ukończone w październiku 2014 r. Wchodzi ono w skład normy MPEG-7, cz. 13 (ISO/IEC 15938-13). CDVS definiuje proces wyznaczania deskryptora oraz określa jego strumień bitowy. Głównym przeznaczeniem tej metody są urządzenia przenośne.
Charakteryzuje się ona wysoką wydajnością oraz niską złożonością. Narzędzie CDVS różni się od starszych metod w procesie wyznaczania deskryptorów, ponieważ wykorzystuje aproksymację oraz kwantyzację – stratną kompresję deskryptorów. W ostatnim roku pojawiły się rozwiązania rozpoznawania aktywności obiektów z wykorzystaniem deskryptorów CDVS.
CDVS definiuje sposób wyznaczania deskryptora dla całego obrazu, ale nic nie stoi na przeszkodzie, by zastosować go do predefiniowanego obszaru, np. okalającego obiekt ruchomy. Przyjrzyjmy się, jak jest tworzony deskryptor CDVS oraz w jaki sposób na jego podstawie dokonuje się rozpoznawanie aktywności.
Pierwszym elementem algorytmu wyznaczania deskryptorów CDVS jest detekcja punktów kluczowych, do której wykorzystuje się strukturę piramidy rozmytych obrazów o różnej skali. Wraz ze zmianą skali zmienia się odpowiednio maska filtru odpowiadającego za rozmycie obrazu. Następnie wyszukiwane są ekstrema lokalne blokowego Laplasjanu filtru Gaussa (LoG) obliczonego w dziedzinie częstotliwości. Ostatnim elementem tej części jest identyfikacja punktów poprzez aproksymację wyników LoG przez wielomiany niskiego rzędu. Powoduje to zmniejszenie buforu pamięci oraz zredukowanie czasu obliczeń. Dla każdego punktu można wyznaczyć wiele lokalnych cech. Metoda CDVS wybiera pewien zbiór cech w taki sposób, aby deskryptor miał długość 512 bajtów, 1 kB, 2 kB, aż do maks. 16 kB. Po wyborze i opisie odpowiednich cech są wyznaczane deskryptory lokalne oraz deskryptor globalny. Chcąc wyznaczyć deskryptory lokalne, uzyskane cechy poddaje się kompresji.
W celu rozpoznania aktywności obiektu na podstawie deskryptorów CDVS można wykorzystać np. deskryptory z grupy Motion Activity. Ich obliczanie opiera się na prostych operacjach wykonywanych na składowych wektorów ruchu. W związku z tym ich wyznaczenie może odbywać się w obrazie skompresowanym, co znacznie przyspiesza proces ekstrakcji cech. Pierwszym z deskryptorów jest intensywność ruchu. Służy on do określenia dynamiki grupy obiektów. Im wyższa jego wartość, tym większy ruch w scenie. Jego wyznaczenie polega na zsumowaniu energii wszystkich wektorów ruchu w ramce obrazu.
Drugim deskryptorem jest 8-przedziałowy histogram kierunków ruchu, opisujący kierunki ruchu obiektów w scenie. W celu jego wyznaczenia obliczany jest kąt dla każdego wektora ruchu, w kolejnym kroku tworzony jest histogram, którego przedziały są od siebie oddalone co 45°.
Trzeci deskryptor opisuje liczbę i rozmiar ruchomych obszarów w scenie, czwarty – intensywność ruchu w największym ruchomym obszarze w stosunku do całego ruchu w scenie. W celu wykrycia, które ramki obrazu zawierają znaną aktywność, należy dokonać śledzenia parametrów deskryptora opisującego wektor, na który składają się przedstawione deskryptory ruchu.
Zastosowania analizy zachowań osób w sklepie
Analiza zachowań osób w sklepie może być wykorzystana w wielu różnych zastosowaniach. Tradycyjni sprzedawcy detaliczni wiedzę na temat zachowań związanych z zakupami klientów zyskiwali dzięki kartom lojalnościowym i ogólnym trendom w dokonywanych transakcjach w punktach POS. Mimo że informacje te dostarczają dużo danych na temat demografii kupującego i tego, co faktycznie kupują, nie pozwalają na wgląd w zachowanie klientów w sklepie.
Jak już wspomniano, za pomocą analizy zachowania klienta można określić popularność danego produktu, która może być powiązana np. z częstotliwością dotykania danego produktu. W tym przypadku można zdefiniować takie aktywności, jak zdejmowanie odzieży z wieszaka, zdejmowanie produktu z półki, podchodzenie do danego wyrobu. Popularność i zainteresowanie może być jednym z przykładów wykorzystania analizy aktywności obiektów.
Druga grupa aktywności, którą można definiować, jest związana z bezpieczeństwem transakcji. Można tu wyróżnić rozpoznawane zachowania, takie jak kradzież odzieży – rozpoznawanie sekwencji zachowań związanych z chowaniem produktu lub odzieży, czy ostatecznie monitorowanie zachowań klientów w sklepie z punktu widzenia ich bezpieczeństwa, czyli bieganie po sklepie, awanturowanie się, kradzież „kieszonkowa”. Wizerunkowo dla sklepu może to być problemem i przekładać się na obroty związane z działalnością handlową.
Kolejnymi aktywnościami, które można wykorzystać w sklepie, jest sprzęgnięcie, zsynchronizowanie informacji z systemu kasowego (i podgląd zawartości paragonów) z analizą wizyjną obrazu z kamery dozorującej obszar płatności. Pozwala to sprawdzić, czy wszystkie produkty są wykładane do skasowania, i czy wszystkie wykładane na ladę (taśmę) są poddawane skanowaniu przez kasjera. Taka analiza pozwala zmniejszyć ryzyko oszustw klientów i pracowników, a także uniknąć ludzkich błędów. W takich miejscach często dochodzi do nadużyć.
Kolejną techniką analizy wspierającą handel jest monitorowanie liczby osób w kolejkach. Jest to bardzo istotne zagadnienie z punktu widzenia optymalizacji pracy jednostki handlowej. Dłuższe kolejki to przede wszystkim niezadowoleni klienci, utrata zysków.
Aktualne rozwiązania mierzą i przewidują długość kolejki oraz czasy oczekiwania, monitorują aktywność strefy, dostarczają raporty w czasie rzeczywistym. Umożliwia to menedżerom sklepów dokonywanie optymalizacji struktury pracowniczej. Na podstawie takich danych można stwierdzać niewystarczającą liczbę pracowników w danych działach, w danych porach dnia, tygodnia i miesiąca oraz optymalizować koszty operacyjne działalności handlowej. Dzięki śledzeniu i pełnemu zakresowi monitorowania ruchu i wzorców zachowań klientów właściciele sklepów mogą podejmować lepsze decyzje operacyjne w zakresie sprzedaży, marketingu, kadry i harmonogramu pracy.
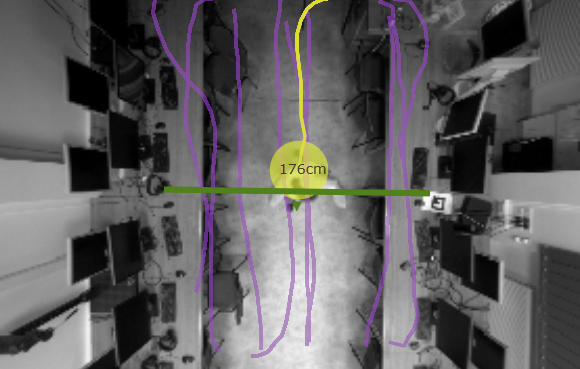
Na potrzeby określania liczby osób przebywających w kolejkach najczęściej stosuje się kamery z sensorem głębi, montowane pod sufitem z obiektywem skierowanym ku dołowi. W przypadku kamer głębi lub kamer stereoskopowych stosuje się algorytmy segmentacji mapy głębi, czyli odległości do każdego obiektu przechodzącego pod kamerą. Równoczesne występowanie we fragmencie obserwowanej sceny wielu osób powoduje powstawanie w mapie głębi lokalnych zmian odległości między kamerą a obiektami. W takich przypadkach bardzo często stosuje się segmentację wododziałową ze względu na traktowanie obrazu mapy głębi jako powierzchni topograficznej. Mapy głębi pokazują lokalne ekstrema. Najmniejsze wartości odległości wskazują czubek naszej głowy. Interpretując takie mapy, w prosty sposób można określić liczebność w danym obszarze. Dodatkowym atutem w przypadku zastosowania tego typu rozwiązań jest określenie demografii kupujących na podstawie analizy wysokości obiektu i toru jego poruszania się (rys. 2).
Kolejną techniką wspierającą merchandising handlowy jest rozmieszczenie towarów w obrębie regału oraz tworzenie ekspozycji promocyjnych. Każda firma, której produkty są obecne w sklepach detalicznych, doskonale wie, jak istotne dla polityki sprzedaży jest dbanie o jej ekspozycję. Budowa i aranżowanie ekspozycji nie jest czynnością oderwaną od biznesowej rzeczywistości. Celem tej techniki jest podniesienie poziomu obrotów, sprzedaży nadmiernego poziomu zapasu towarów oraz wprowadzenie nowych produktów na rynek. Detalista ma tak zaprezentować i zaoferować towar w miejscu sprzedaży, aby zachęcić konsumenta do ich zakupu. Źle zorganizowany układ sali sprzedaży czy brak czytelnych wskazówek informacyjnych zmuszają klienta do poszukiwań, zniechęcając go tym samym do powtórnej wizyty.
Analizy zawartości półek sklepowych można dokonać za pomocą narzędzi analizy obrazów. Pozwala ona kontrolować, jakie produkty znajdują się na półkach, i czy w pewnym momencie nie zaczyna ich brakować. Można ją łatwo przeprowadzić, stosując jedną z technik wyznaczania cech lokalnych obiektów (zaprezentowanych przy okazji omawiania analizy zachowań) oraz porównania tych cech ze zbiorem utrzymywanym w bazie danych.
W celu prawidłowego przeprowadzenia takiej analizy kamera powinna być zamontowana naprzeciwko analizowanego regału. Algorytmy analizują obrazy przesyłane strumieniowo przez kamerę ze sklepu, dokonują detekcji produktów, analizując opakowania z dostępną bazą produktów. W sposób zautomatyzowany i ciągły monitorują zawartość półek, ich niewłaściwe umieszczanie, a zwłaszcza brak produktów na półkach, mimo że są dostępne np. w magazynie. Firmy handlujące towarami konsumpcyjnymi mogą też monitorować, czy ich produkty są wyświetlane zgodnie z wynegocjowanymi umowami. Wykorzystanie kamer nie wymaga zmian w infrastrukturze półkowej, jedynie narzuca konieczność wdrożeniem sieci kamer.
Coraz częściej pojawia się także rozwiązanie „wirtualnego lustra”, które może być ustawione jako element tradycyjnego sklepu. Jest to rozwiązanie tzw. wzbogacanej rzeczywistości (augmented reality), w której rzeczywisty obraz jest uzupełniany obrazem generowanym komputerowo. System taki opiera się na zastosowaniu tradycyjnej kamery wraz z kamerą głębi. W czasie rzeczywistym, na podstawie pomiarów ciała z wykorzystaniem sensorów głębi następuje trójwymiarowe analizowanie sylwetki osoby stojącej przed kamerą oraz automatyczne dopasowanie i skalowanie modelu danej odzieży do klienta, a następnie renderowanie w czasie rzeczywistym obrazu sukienki na obrazie z tradycyjnej kamery. Obraz wyjściowy jest prezentowany na dużym monitorze w taki sposób, że klient w sklepie ma wrażenie, że jest ubrany w daną odzież i stoi przed lustrem. Zmiany odzieży dokonuje się poprzez interfejs użytkownika sterowany gestami. Rozwiązanie to charakteryzuje się przede wszystkim zwiększeniem atrakcyjności postrzegania danego sklepu, ma także wiele innych walorów, np. pozwala zmniejszyć kolejkę do przymierzalni, określić płeć i wiek klientów, popularność odzieży, kolor czy fason.
Wykorzystanie paneli – monitorów informacyjnych dedykowanych klientowi jest kolejnym trendem w rozwiązaniach wspierających handel detaliczny. Analiza w czasie rzeczywistym toru poruszania się klienta po sklepie wraz z informacją o jego aktywności (zainteresowaniu produktami) może służyć do kierunkowego na jego torze poruszania się wyświetlania spersonalizowanych reklam produktów.
Podsumowanie
Przedstawione rozwiązania pozwalają sprzedawcom detalicznym znacznie zredukować ich zależność od miękkich danych, zastępując je rzeczywistymi informacjami, które pomagają zwiększyć sprzedaż, optymalizować operacje i poprawić jakość obsługi klienta. Opisane techniki nie wyczerpują możliwości analizy treści sekwencji wizyjnych wspierających handel detaliczny, a zostały zaprezentowane jedynie informacyjnie w celu przedstawienia kierunków i trendów rozwoju systemów analizy obrazu dla tego typu zastosowań.
dr inż. Sławomir Maćkowiak
Ekspert ds. systemów dozoru wizyjnego, pracownik naukowy Katedry Telekomunikacji Multimedialnej i Mikroelektroniki, wykładowca Wydziału Elektroniki i Telekomunikacji Politechniki Poznańskiej.
Od ponad 20 lat związany zawodowo i naukowo z przetwarzaniem obrazów, w tym w szczególności z zagadnieniami z zakresu inteligentnej analizy treści sekwencji wizyjnych systemów jedno- i wielokamerowych.
Ma na swoim koncie patenty z zakresu analizy treści obrazów w Unii Europejskiej i USA.







{kind=link}