

























Jan T. Grusznic
Czytelny i użyteczny obraz nie wynika tylko z większej liczby pikseli na przetworniku – wiedzą o tym uczestnicy prowadzonych przeze mnie kursów. Im dalej w rozdzielczość, tym więcej problemów, trudnych do rozwiązania na poziomie instalacji bez specjalistycznej wiedzy, narzędzi i technologii. Rozdzielczość full HD jest obecnie standardem, punktem odniesienia wielkości obrazu (kilka lat temu był nim format 4CIF). Postęp technologiczny o funkcji wykładniczej każe twierdzić, że już w roku 2020 rozdzielczość 2160p (znana jako 4K) zastąpi 1080p (full HD). Spowoduje to kolejne zmiany w branży telewizji dozorowej. A ta jest bez wątpienia najszybciej rozwijającym się działem elektronicznych systemów zabezpieczeń.
Od wielu lat obserwujemy wyraźny wpływ zmian dokonujących się na rynku konsumenckich dóbr elektronicznych na rozwiązania proponowane przez producentów elementów systemów telewizji dozorowej. Pojawiły się w naszej branży produkty ze świata fotografii, kamer sportowych czy urządzeń mobilnych, głównie smartfonów. Wielu producentów tych urządzeń przeniosło ciężar przekazu reklamowego z rozdzielczości na elementy optyczne, takie jak stabilizacja optyczna, skuteczniejsze i szybsze ogniskowanie, zwiększona poklatkowość (zapewniająca uzyskanie efektu spowolnienia – slow motion) czy krótka głębia ostrości (tryb portretowy). Optyka stała się języczkiem u wagi nie tylko dla producentów dóbr konsumenckich, ale również producentów sprzętu profesjonalnego do pracy ciągłej przeznaczonego do przechwytywania obrazu.
Waga optyki
Czytelny, szczegółowy obraz to wynik zgrania przede wszystkim dwóch elementów: układu optycznego i przetwornika obrazu. Okazuje się, że uzyskanie idealnego dopasowania nie jest takie proste, jak by się to wydawało na pierwszy rzut oka. Zwłaszcza dla wyższych rozdzielczości. Ileż to razy do kamery 5-megapikselowej wkręcałeś obiektyw 5-megapikselowy, a obraz był daleki od ideału? Trochę bez ostrości (bo nawet z automatycznym i bardzo pomocnym asystentem ustawiania pozycji przetwornika nie udało jej się nigdzie w obrazie znaleźć), na dodatek z aberracją sferyczną i jeszcze mało kontrastowy. Opisane przeze mnie efekty są związane właśnie z nieprawidłowym dopasowaniem optyki do przetwornika kamery, a konkretnie – z punktem ogniskowania, który jest większy niż płaszczyzna pojedynczego piksela matrycy światłoczułej, przez co naświetla sąsiednie piksele. W rezultacie obserwujemy zmniejszenie czytelności detali w obrazie – rozdzielczość optyczna ulega degradacji. Jednocześnie gdy punkt ogniskowania jest mniejszy niż piksel, na obrazie będą widoczne błędy w postaci różnokolorowych fal interferujących ze sobą (rys. 1).

źródło: www.visualabode.com.au
Efekt ten, zwany morą, jest dość często widziany na obrazach z kamer dostarczających sygnał analogowy Pojawia się, gdy rozdzielczość układu optycznego jest większa niż rozdzielczość przetwornika kamery. Można go zredukować lub pozbyć się całkowicie dzięki zastosowaniu filtrów dolnoprzepustowych, które powodują efekt lekkiego rozmycia i delikatną redukcję kontrastu. Redukcję efektu mory umożliwia również delikatne „rozostrzenie”, tj. zgubienie ostrości.
Niestety w przypadku zastosowania obiektywu o mniejszej zdolności rozdzielczej niż wymaga tego przetwornik, obraz będzie miał gorszą czytelność detali. Teoretycznie można elektronicznie „doostrzać” obraz za pomocą odpowiednich filtrów cyfrowych, jednak efekt jest na ogół daleki od satysfakcjonującego.
Ponieważ niemal od dekady na rynku telewizji dozorowej obserwujemy erozję jakości podawanych danych (niekoniecznie wynikających ze złych intencji producentów, raczej z braku odpowiedniego unormowania wykonywanych badań), problem ten w końcu dotknął również deklarowanych rozdzielczości obiektywów. Na rynku są dostępne obiektywy megapikselowe: 5-Mpix, 3-Mpix lub full HD lub 4K. Tymczasem podłączenie wyraźnie dookreślonej optyki do kamery o „takiej samej” rozdzielczości daje często tak różne efekty, które obserwujemy na wynikowym obrazie. Skąd brak powtarzalności, skoro wartości się zgadzają? Powodem jest właśnie brak zgrania tych dwóch elementów.
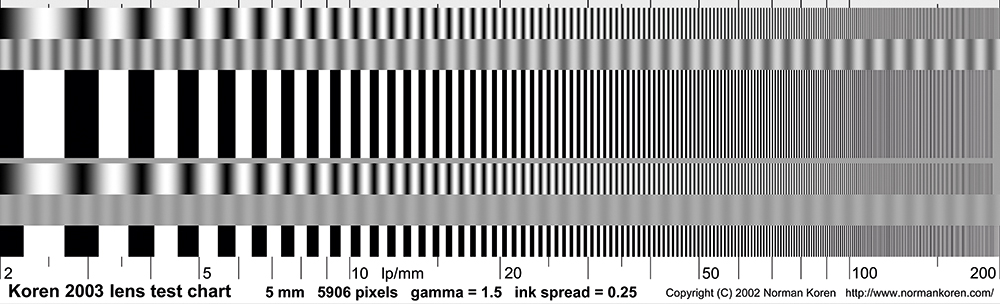
Zacznijmy od powodu najprostszego: rozdzielczości obiektywów nie mierzy się w pikselach, ale w parach linii przypadających na 1 mm [lp/mm]. Rozdzielczość 180 lp/mm oznacza, że na 1 mm można dojrzeć 360 linii czarnych i białych ułożonych naprzemiennie.
źródło: www.normankoren.com
Na rys. 2 pokazano przykładową planszę testową, za pomocą której testuje się rozdzielczość elementów optycznych (z powodu ograniczeń rozdzielczości wydruku część linii jest widoczna jako szary fragment). Rozdzielczość obiektywu y [lp/mm] dla przetwornika 1/2,5” o rozdzielczości 4K będzie wynosić ok. 308 lp/mm zgodnie ze wzorem:
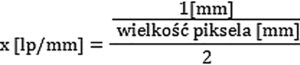
Zakładając, że wielkość piksela dla przetwornika 1/2,5” o rozdzielczości 4K wynosi typowo 1,62 µm (uwaga: warto tę wartość zweryfikować w karcie katalogowej producenta przetwornika) oraz ujednolicając jednostki 1,62 µm = 0,00162 mm (1 mm = 1000 µm), otrzymamy:
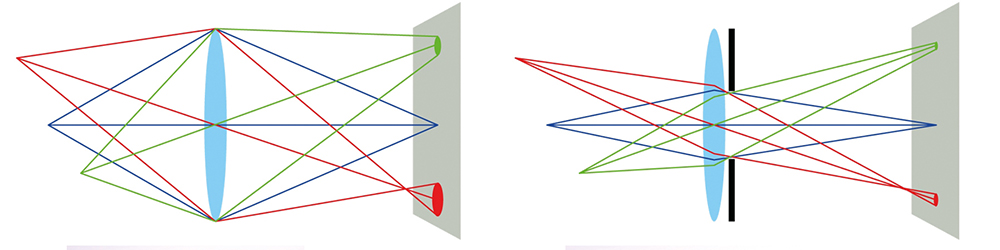
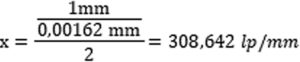 Gdyby wielkość przetwornika była większa, tzn. piksel byłby większy i miał np. 4,09 µm, wtedy rozdzielczość obiektywu nie musiałaby przekraczać 122 lp/mm. Zatem dla większego piksela na przetworniku potrzebny jest obiektyw o mniejszej zdolności rozdzielczej. Należy przy tym zauważyć, że wyliczona wartość odnosi się do każdego punktu optyki. Niestety ze względu na obecne ograniczenia technologiczne na etapie produkcji zdolność rozdzielcza soczewek różni się między środkiem a sferą obiektywu. Dla przykładu firma Kowa, jako jeden z nielicznych producentów, dla obiektywu 1/2” LMVZ3510M-IR deklaruje rozdzielczość w środku optyki 200 lp/mm, zaś w rogu kadru 120 lp/mm. W jej karcie katalogowej ujęto również dopasowanie do wielkości piksela o wielkości 2,5 µm (przy czym wielkość plamki dla 120 lp/mm będzie wynosić ~4 µm). Teoretycznie oznacza to, że obiektyw nadaje się do kamer aż 5 Mpix, natomiast należy się spodziewać widocznego efektu rozmycia ostrości w rogach kadru. Efekt ten można próbować zredukować przez zamknięcie przysłony, aby ograniczyć przenikanie promieni tylko dośrodkowej części soczewki, co pokazano na rys. 3.
Gdyby wielkość przetwornika była większa, tzn. piksel byłby większy i miał np. 4,09 µm, wtedy rozdzielczość obiektywu nie musiałaby przekraczać 122 lp/mm. Zatem dla większego piksela na przetworniku potrzebny jest obiektyw o mniejszej zdolności rozdzielczej. Należy przy tym zauważyć, że wyliczona wartość odnosi się do każdego punktu optyki. Niestety ze względu na obecne ograniczenia technologiczne na etapie produkcji zdolność rozdzielcza soczewek różni się między środkiem a sferą obiektywu. Dla przykładu firma Kowa, jako jeden z nielicznych producentów, dla obiektywu 1/2” LMVZ3510M-IR deklaruje rozdzielczość w środku optyki 200 lp/mm, zaś w rogu kadru 120 lp/mm. W jej karcie katalogowej ujęto również dopasowanie do wielkości piksela o wielkości 2,5 µm (przy czym wielkość plamki dla 120 lp/mm będzie wynosić ~4 µm). Teoretycznie oznacza to, że obiektyw nadaje się do kamer aż 5 Mpix, natomiast należy się spodziewać widocznego efektu rozmycia ostrości w rogach kadru. Efekt ten można próbować zredukować przez zamknięcie przysłony, aby ograniczyć przenikanie promieni tylko dośrodkowej części soczewki, co pokazano na rys. 3.
źródło: materiały szkoleniowe Axis Communications
Niestety przy dużych rozdzielczościach pojawia się problem z efektem dyfrakcji, której moment ujawnienia w dużym stopniu zależy od wielkości piksela. Im mniejszy piksel, tym szybciej. Dyfrakcja, czyli ugięcie fali na krawędzi przeszkody – w omawianym przypadku w środowisku optycznym – ma wpływ na wielkość tzw. plamki Airy’ego, zwanej również krążkiem dyfrakcyjnym. Ostry, czytelny obraz powstaje wtedy, gdy plamka Airy’ego jest wielkości pojedynczego piksela. Im jest ona większa, tym mniej czytelny staje się obraz, co można zaobserwować na rys. 4.

Plamka Airy’ego wielkości jednego piksela przetwornika

Wielkość plamki Airy’ego można wyliczyć z uproszczonego wzoru X = 1,22 x ? x F (gdzie X – wielkość plamki, ? – długość fali świetlnej, F – otwór przysłony), przy założeniu, że:
• przysłona ma kształt idealnego koła,
• obiektyw jest pozbawiony wszelkich wad optycznych (obliczenia są wykonywane dla obiektywu idealnego).
W przypadku kamery 2160p, dla której szacuje się, że pojedynczy piksel ma ok. 1,62 µm (dla przetwornika ~1/2.5”) przysłona ograniczona dyfrakcją ma wartość F2.0. Natomiast zamknięcie przysłony do wartości F4.0 spowoduje dwukrotną stratę rozdzielczości obrazu. Oznacza to, że przy tej wartości przysłony jeden punkt światła jest odbierany przez otaczające piksele matrycy (rys. 5).
 |
 |
| Rys. 5. Ilustracja zwiększonej plamki Airy’ego na skutek zamknięcia przysłony Każdy z mniejszych kwadratów na obu rysunkach odpowiada wielkości piksela o długości boku 1,62 µm. Średnica wielkości plamki Airy’ego dla przysłony F2.0 (po lewej stronie) dla długości fali 650 nm wynosi 1,58 µm. Wielkość plamki dla przysłony F 4.0 (po prawej) wynosi 3,17 µm. Widoczne jest naświetlenie sąsiednich pikseli. |
|
Producenci kamer zauważyli istotę problemu już jakiś czas temu. W efekcie podjętych działań opracowano odpowiednie algorytmy i mechanizmy sterujące przysłoną. Przykładem może być opracowanie w 2009 r. przez firmę Kowa, we współpracy z Axis Communications, obiektywów z automatyką P-iris. Mechanizm jest oparty na silniku krokowym, a każdy krok oznacza konkretną wartość przysłony. Ponieważ nie istnieją standardy co do liczby kroków i przypisania doń konkretnych wartości F, każdy typ obiektywów wyposażonych w mechanizm P-iris będzie się różnił tymi wartościami między sobą. Stąd producenci tworzą pliki, które są swoistymi sterownikami. Po ich wgraniu do kamery ta porównuje wartości wielkości piksela (na ogół podane w oprogramowaniu układowym) z danymi zawartymi w pliku i określa optymalny poziom zamknięcia przysłony, który zapewnia maksymalną głębię ostrości, przy jednoczesnym utrzymaniu wysokiego kontrastu i czytelności szczegółów. Możliwość ustawienia precyzyjnie przysłony daje bardzo wymierne korzyści. Przede wszystkim wraz z zamykaniem przysłony zwiększa się głębia ostrości, czyli zakres obszaru na obrazie, który jest ostry. Zamknięcie przysłony pomaga również w usunięciu błędów optycznych, jakimi bez wątpienia jest aberracja sferyczna powodująca niewyraźny obraz na brzegach kadru. Z drugiej strony P-iris zabezpiecza przed zbytnim domknięciem lamelek przysłony i obniżeniem szczegółowości obrazu przez uwidocznienie się efektu dyfrakcji właśnie. Co ciekawe, technologia ta nie została opatentowana, co pozwala wykorzystać to rozwiązanie przez wszystkie firmy producenckie.
Podobnie ma się sprawa z technologią i-CS, rozwiązaniem opracowanym również przez Axis, ale z firmą Computar. i-CS obok wykorzystania technologii precyzyjnego sterowania przysłoną P-iris zapewnia również zdalne sterowanie zakresem ogniskowych oraz ostrością. Zdalne ustawianie soczewek to nie luksus, tylko potrzeba. Już dla rozdzielczości full HD ręczne ustawianie ostrości jest męczące – dla rozdzielczości 4K to istny koszmar. i-CS jest rozwiązaniem dla obiektywów przeznaczonych do wszystkich kamer z montażem CS i obsługujących ten standard.
Ratunek we Fresnelu
Obecnie wybór modeli obiektywów oraz kamer zgodnych ze standardem UHD jest ograniczony (producent oferuje tylko kilka modeli). Niemniej sytuacja wydaje się rozwojowa, bowiem powoli wprowadzane są nowe przetworniki o większej dynamice i większej czułości. Wraz z nimi pojawiają się również obiektywy o rozdzielczościach zbliżonych do przykładowych ok. 308 lp/mm oraz tworzących plamkę Airy’ego dopasowaną do wielkości piksela (~1,62 µm). Dalsze zwiększanie rozdzielczości kamer będzie wymagać albo zwiększenia wielkości przetworników, a co za tym idzie rozmiarów pojedynczego piksela, albo zmiany koncepcji budowy obiektywów. Obecne obiektywy wykorzystują zjawisko załamania światła przez soczewki (skupiające lub rozpraszające), które wykonuje się ze specjalnych gatunków szkła lub innych przezroczystych materiałów (np. kwarcu, fluorytu lub plastiku). Łącząc kilka soczewek o odpowiednio dobranej krzywiźnie i współczynnikach załamania, można zbudować obiektyw dający wyraźny i pozbawiony zniekształceń obraz. Jednak obraz pochodzący z układu zwykłych soczewek refrakcyjnych traci z powodu znacznej aberracji chromatycznej (związanej z rozszczepieniem światła).Współczynnik załamania jest różny dla różnych długości fal, które po przejściu przez soczewkę skupiają się w różnych punktach. W rezultacie dyspersja chromatyczna musi zostać skompensowana przez wprowadzenie dodatkowych soczewek, jako że liczba fal do skorygowania wzrasta. Dublet achromatyczny koryguje dwie długości fal, apochromat – trzy, a superachromat – cztery. W efekcie wprowadzanie kolejnych środowisk korekcyjnych zwiększa masę i wielkość obiektywu.
Nowy rodzaj soczewek opracowany przez zespół uczonych z Harvardu został zaprojektowany tak, aby skupiać trzy długości fal bez zwiększania grubości i wielkości soczewki. W zeszłym roku zespół profesora Federico Capasso opracował nową, płaską soczewkę, która jednakowo odchyla fale widzialne o różnej barwie, czyli światło. Dzięki temu tworzony jest obraz o wysokiej jakości. Dziesięciokrotnie cieńsza od włosa soczewka wykorzystuje zjawisko dyfrakcji – światło ugina się dzięki mikroskopijnym strukturom wytworzonym w materiale soczewki. Taka „superachromatyczna” soczewka może powstać z każdego przezroczystego materiału – np. szkła lub plastiku. Cieńsze od papieru soczewki mogłyby znaleźć zastosowanie w obiektywach aparatów cyfrowych i smartfonów, kamerach dronów i satelitów, medycznych endoskopach, superlekkich okularach, jak również w kamerach CCTV.
Nowa kompresja, stare problemy
Wyższe rozdzielczości wymagają nowych metod kompresji. Obecnie stosowany standard dekodera H.264 jest ograniczony wielkością obrazu składającego się z maks. 9 437 184 pikseli, które jest w stanie zdekodować maks. 56,3 kl./s. Ograniczenie to wynika z samej konstrukcji dekodera, który do zdekodowania obrazów używa wirtualnego buforu o określonej pojemności. Dotychczas H.264 sprawdzał się bardzo dobrze, przede wszystkim ze względu na elastyczną budowę. Dzięki niej producenci mogli stworzyć różne rozwiązania zmniejszające liczbę przesyłanych danych, przy jednoczesnym utrzymaniu wysokiej jakości obrazu i zgodności z wymaganiami standardu. Do takich rozwiązań można zaliczyć zmienną w czasie wartość GOP czy dynamiczne ROI zwiększające lub zmniejszające poziom kompresji wybranych części obrazów. Niestety ograniczenia w budowie obecnie wykorzystywanego algorytmu kodowania sekwencji obrazów powodują, że trzeba będzie „przesiąść się” do nowego i niepoznanego jeszcze „w boju” standardu H.265 (HEVC – High Efficiency Video Coding), który przesuwa maksymalną wielkość obrazu z 2160p do 4320p (35 651 584 piksele).
Obecną wiedzę o nowym standardzie kompresji branża czerpie raczej z przekazów marketingowych aniżeli z fachowych czasopism. Dlatego jesteśmy zewsząd atakowani informacjami, jakoby H.265 miał zmniejszyć zapotrzebowanie na pamięć masową o 50%. Stwierdzenie to nie jest kłamliwe, jeżeli przyjmiemy kilka podstawowych założeń:
- poziom oświetlenia w scenie jest na tyle wysoki, że nie jest wymagane elektroniczne wzmacnianie sygnału;
- poklatkowość zapisywanego strumienia wizyjnego wynosi 25 kl./s;
- rozdzielczość obrazu wynosi co najmniej 1080p.
Warto zauważyć, że wspomniane zmniejszenie pamięci masowej o 50% w porównaniu do H.264 dotyczy standardu H.264 High Profile używanego w telewizji programowej, który zakłada chociażby wykorzystanie ramek B, raczej niewykorzystywanych w systemach dozoru wizyjnego ze względu na większe opóźnienia w prezentacji obrazu. Zatem deklarowana wartość redukcji liczby danych nie musi przełożyć się na ewentualne wyniki uzyskane w systemach CCTV. Tak czy inaczej, ograniczenie liczby przesyłanych danych w nowym standardzie kodowania będzie możliwe dzięki wprowadzeniu wielu unowocześnień do H.264. Zmianą pod względem technicznym wobec dotychczasowych rozwiązań jest przede wszystkim fakt, że w standardzie H.265 makrobloki zastąpiono złożoną konstrukcją CTB (Coding Tree Block) o maksymalnych rozmiarach 64 x 64 piksele (16 razy większe niż w H.264). Dzięki temu uzyskuje się bardziej wydajne kodowanie, szczególnie dla wyższych rozdzielczości obrazu, niestety przy dłuższym czasie ich przeliczania. Tak duże bloki mogą być odpowiednio podzielone na mniejsze w zależności od szczegółowości danego fragmentu obrazu (rys. 6). Ponadto wykorzystuje się tu równoległe dekodowanie, czyli jednoczesne przetwarzanie różnych części obrazu, co przyśpiesza odtwarzanie i umożliwia obsługę niekompatybilnych z H.264 procesorów wielordzeniowych. Pojawia się tu też Clean Random Access, czyli selektywna funkcja pomagająca zwiększyć szybkość transmisji. Niestety H.265 nadal nie pozwala na skalowanie wideo, choć funkcja ta jest planowana w przyszłości.


Wprowadzanie nowego standardu kodowania nie obędzie się bez zgrzytów. Rynek telewizji dozorowej ma już za sobą trudne doświadczenie przejścia z kompresji MPEG-4 na H.264. Zapoczątkowany proces zmiany technologicznej w 2006 r. zakończył się definitywnie w 2011 r., gdy na rynek weszły ostatnie kamery i rejestratory wykorzystujące kompresję MPEG-4. W tym 5-letnim okresie wielokrotnie okazywało się, że system dopasowany do starszego algorytmu kodowania międzyobrazowego nie współpracował z nowym. Brakowało pamięci, mocy obliczeniowej, właściwych kart graficznych, aby właściwie zaprezentować płynny strumień wideo H.264. Jednostka obliczeniowa przygotowana do współpracy z nowym algorytmem niekoniecznie radziła sobie z MPEG-4.
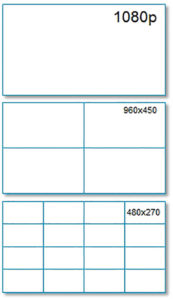
Jestem daleki od pesymizmu – z H.265 wiążę wielkie nadzieje – ale wiem, że czas „przesiadania się” z obecnego standardu H.264 na H.265 nie będzie okresem łatwym. Nie ukrywają tego zresztą producenci sprzętu audiowizualnego na rynkach profesjonalnym i amatorskim. Wysokie rozdzielczości już w standardzie dekodera H.264 wymagają ogromnych mocy obliczeniowych. W przypadku H.265 te zasoby będą musiały być jeszcze większe. W aplikacjach klienckich VMS oczywisty okaże się wymóg wykorzystania mocy obliczeniowej procesorów graficznych (GPU). Prezentacja obrazów w trybie wielopodziału będzie determinować wykorzystanie dynamicznych rozdzielczości dopasowujących się do wielkości segmentu, w którym jest prezentowany obraz (rys. 7). Być może wykorzystanie koncepcji chmury i tzw. cienkich klientów, polegające na przesyłaniu zawartości ekranu w postaci jednego strumienia wizyjnego między serwerem a klientem, stanie się powszechnym rozwiązaniem?
Szumy w układach wysokich mocy obliczeniowych
Gordon Moore, szef laboratorium firmy Fairchild Semiconductor, opublikował 50 lat temu w branżowym periodyku elektronicznym artykuł, w którym przedstawił wizjonerską prognozę. Stwierdził, że liczba dyskretnych komponentów możliwych do upakowania w pojedynczym czipie komputerowym będzie się co rok podwajała, podczas gdy cena tych czipów pozostanie stała. Mowa oczywiście o „prawie” Moore’a, które najpewniej będzie obowiązywało jeszcze około sześciu stuleci*, choć początkowo twórca tej zasady przewidział jej poprawność przez 10 lat. Podczas rozwoju technologii półprzewodnikowych w tempie zgodnym z Prawem Moore’a wyłoniła się druga, mniej znana zasada skalowania, sformułowana przez Roberta Dennarda. Mówiła ona, że w miarę zmniejszania się rozmiarów tranzystorów ich gęstość energetyczna pozostaje stała.
Oznacza to, że zużycie energii zmienia się proporcjonalnie do zmian powierzchni (mniejsza powierzchnia to mniejsze zużycie energii). Mniejsze tranzystory potrzebują mniejszego napięcia i natężenia prądu, tak więc wraz z kolejnymi generacjami czipów o coraz większej liczbie tranzystorów, będą one wydzielały mniej ciepła i zużywały mniej energii. Ale to właśnie ta zasada zawiodła, a nie Prawo Moore’a. Nagle okazało się, że poniżej pewnych rozmiarów tranzystorów pojawiają się prądy upływu, prowadzące do eskalującego się nagrzewania układu. W przetwornikach obrazu kamer fotodiody tworzące matrycę generują elektrony nawet w zupełnej ciemności. Jest ich tym więcej, im układ jest bardziej rozgrzany. Te generowane samoistnie elektrony sumują się z elektronami generowanymi w trakcie naświetlania przetwornika. Prąd upływu jest różny dla poszczególnych pikseli, co daje dodatkowe zróżnicowanie jasności poszczególnych punktów obrazu. Ich jasność zależy od temperatury – im wyższa, tym jaśniejszy będzie punkt pochodzący z piksela.
Wzrost mocy obliczeniowych po stronie kamer jest oczywistą konsekwencją zwiększania rozdzielczości. Większa liczba pikseli na przetworniku, wydajniejsze kodowanie oraz tendencja przenoszenia obliczeń z centralnych jednostek do tzw. urządzeń brzegowych wymuszają stosowanie układów o większej mocy, która niestety generuje coraz więcej ciepła, a ono negatywnie wpływa na jakość obrazu w postaci widocznego szumu, który nie zależy od liczby fotonów padających na matrycę. Szum związany z temperaturą sensora CMOS ma charakter losowy i w każdej klatce inny rozkład przestrzenny. Nie ma prostej możliwości usunięcia szumu, można go jedynie uśrednić, stosując np. filtrację dolnoprzepustową, kosztem utraty części informacji. Drugą możliwością (acz ograniczoną do ujęć statycznych) jest wykonanie serii zdjęć i ich uśrednienie. Niedoskonałości obrazu stają się bardziej widoczne wraz ze wzrostem jego rozdzielczości. Oznacza to, że oprócz zwiększania mocy obliczeniowej to szybkie odprowadzanie ciepła z układu, a przede wszystkim jego separacja od obszaru instalacji układu CMOS staje się polem innowacyjnych rozwiązań inżynieryjnych, mających na celu utrzymanie wysokiej jakości obrazu.
W najbliższych latach…
Liczba pikseli przestała być wyłącznym wyznacznikiem jakości. Stanowi jeden z elementów, które oddziałując na siebie, pozwalają na osiągnięcie spektakularnych rezultatów. Standaryzacja SMPTE, innowacje w świecie fotografii, optyki oraz rozwiązania kompresji obrazu na rynku multimediów będą głównymi siłami, które pokierują dalszymi losami rynku CCTV. Wysokie rozdzielczości wpłyną również na wiele elementów powiązanych, takie jak analiza obrazu, która od jakiegoś czasu zyskuje szersze uznanie w naszej branży. Do tego dojdzie wirtualizacja strumieni, zapewniająca uzyskanie z jednej fizycznej kamery wiele wirtualnych, dostarczających obrazy z wybranych pól obserwacji. Istotne staną się kwestie związane z dekodowaniem obrazów i ich odpowiednią prezentacją. Pojawienie się kamer wysokich rozdzielczości, które zmusiły do uznania wagi optyki w tworzeniu wysoko jakościowych obrazów i wykorzystania nowych standardów kompresji, to dopiero początek fascynujących zmian w CCTV.
* Granicą jest tzw. granica Bekensteina – maks. ilość informacji, którą można umieścić w skończonym obszarze przestrzeni o skończonej ilości energii. Z niej wynika granica Bremermanna, określająca maks. szybkość obliczeń możliwą dla fizycznego układu w naszym wszechświecie. Wynika z niej m.in. że układ o masie Ziemi byłby w stanie przeprowadzić ok. 1075 operacji na sekundę.
Jan T. Grusznic
Z branżą wizyjnych systemów zabezpieczeń związany od 2004 r. Ma bogate doświadczenie w zakresie projektowania i wdrażania rozwiązań dozoru wizyjnego w aplikacjach o rozproszonej strukturze i skomplikowanej dystrybucji sygnałów. Ceniony diagnosta zintegrowanych systemów wspomagających bezpieczeństwo.
[1] https://tools.ietf.org/html/draft-ietf-payload-rtp-h265-15 [2] http://www.tvprzemyslowa.pl/standard-kompresji-h265/ [3] Mike Callahan: Elemental Insights Webcast | HEVC / H.265, 7/02/2013 [4] Gary J. Sullivan, Jens-Rainer Ohm, Woo-Jin Han, and Thomas Wiegand: Overview of the High Efficiency Video Coding (HEVC) Standard, IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 22, NO. 12, DECEMBER 2012 [5] M. Domański, T. Grajek, J. Marek, Zaawansowana kompresja cyfrowych sygnałów wizyjnych – standard AVC/H.264, „Systemy Alarmowe” nr 2/2005 [6] Andreas Unterweger, What is new in HEVC/”H.265”?, Department of Computer Sciences University of Salzburg, 17/10/2012 [7] Kalkulator: Limit rozdzielczości matrycy – dyfrakcja, alphacorner.eu [8] Initial Report of the UHDTV Ecosystem Study Group, © 2013 by the Society of Motion Picture and Television Engineers (SMPTE) [9] Understanding ultra high definition television, Ericsson white paper, Uen 284 23-3266 | November 2015 [10] Limitations on Resolution and Contrast: The Airy Disk, http://www.edmundoptics.com/ , 13/03/2016 [11] Mark Peterson: How to calculate image resolution, Theia Technologies, 2009 [12] M. Peterson, M.S. Wilson, What’s a Megapixel Lens and Why Would You Need One? Theia Technologies, Infinova, 5/6/2011 [13] 4K CCTV Won’t Deliver 4K Images without the Right Lenses – and that’s a Huge Challenge, www.ifsecglobal.com, 6/10/2015 [14] 50 lat Parawa Moore’a. Ile jeszcze wykładniczego postępu przed nami?, Adam Galański, www.dobreprogramy.pl/50-lat-Prawa-Moorea.-Ile-jeszcze-wykladniczego-postepu-przed-nami,News,62451.html







{kind=link}