









Dolina niesamowitości

Jan T. Grusznic
Obecnie od producentów zabezpieczeń technicznych oczekuje się znacznie więcej niż dotychczas. Przełom w uczeniu maszynowym, łączenie urządzeń do jednej, globalnej sieci i potwornie duże ilości agregowanych danych – wszystko to zwiększa apetyt na automatyzację procesów związanych z bezpieczeństwem. Historia uczy, że wdrożenia nowych technologii wymagają czasu i niemałej wiedzy. W torii jesteśmy lepiej przygotowani na nowe dzięki doświadczeniom z początków kontekstowej analizy obrazu.
Wyciągając wnioski, rozmawiając o oczekiwaniach, dzieląc się wiedzą nt. nowych technologii, mamy realny wpływ na rozwój naszej branży i powstanie Security 3.0. Na początku maja na konferencji I/O Google przedstawiciele koncernu z Mountain View zaprezentowali swoje najnowsze dzieło: Duplex. Po kilku latach pracy nad algorytmami zamieniającymi tekst pisany na mowę, zabawy z syntezatorami mowy, analizowania spektrogramów z zapisu rozmów osób Alphabet1) zadziwił świat, przeskakując „dolinę niesamowitości”. Najnowszy produkt koncernu potrafi zarezerwować wizytę u fryzjera lub stolik w restauracji – przez telefon! Rozmówca-człowiek absolutnie nie odnosi wrażenia, że rozmawia z maszyną. Duplex wstawia bowiem bardzo typowe dla ludzi monosylaby pojawiające się w dialogu, a także zwroty sygnalizujące namysł, typu „hmmm” [1]. To niesamowity postęp dokonany przez ludzkość, niczym lądowanie na Księżycu w 1969 r. Oto algorytmy napędzane sztuczną inteligencją (AI) i ogromnymi zbiorami danych są w stanie porozumieć się z człowiekiem i coś z nim ustalić, korzystając z języka naturalnego. Nawet jeśli ta funkcjonalność jest ograniczona do dokonania rezerwacji w usługach, Duplex robi piorunujące wrażenie. Wrażenie, które po chwili przeradza się w trwogę i niechęć. Na myśl przychodzi tytułowa „dolina niesamowitości” – termin wprowadzony przez konstruktora robotów Masahiro Mori [2]. Określa on próg realizmu w zachowaniu i wyglądzie robotów, którego przekroczenie u wielu osób wywołuje nieprzyjemne uczucia (rys. 1).
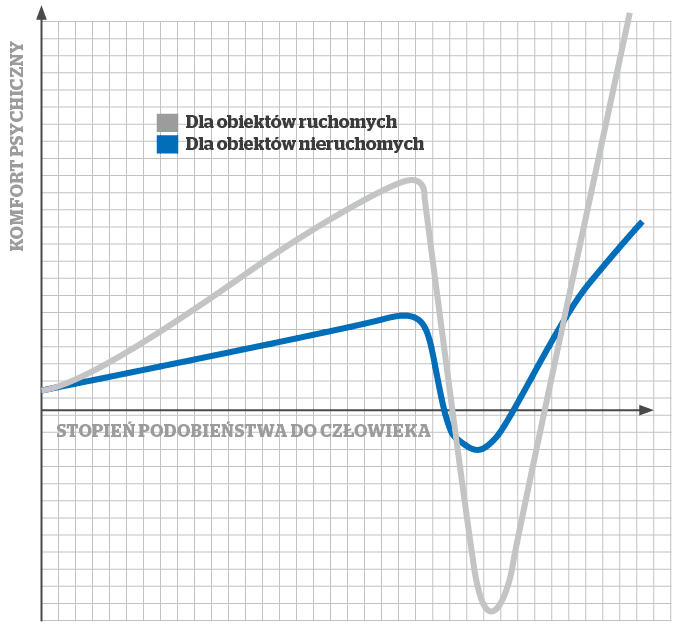
W uproszczeniu chodzi o to, że zazwyczaj ludzie reagują normalnie na widok maszyny typu Aibo lub WALL-E, czy szkieletu pokrytego kablami, wykonującego niezdarne ruchy. Nie wszyscy są jednak w stanie ze spokojem przyjąć widok robota lub animowanej postaci filmowej do złudzenia przypominającej wyglądem lub zachowaniem człowieka. Szczególnie gdy jest to kopia bliska oryginałowi. Im bardziej zaciera się granica między człowiekiem a maszyną, tym poczucie dyskomfortu staje się większe. Efekt ten potęgują nienaturalne, wręcz irracjonalne decyzje (ruchy), których człowiek by nie powziął (wykonał). Postęp technologiczny ciągle przesuwa granicę tolerancji doliny niesamowitości. Istnieje teza mówiąca, że termin ten zdezaktualizował się na skutek ciągłego obcowania z techniką wspomagającą nas w codziennych obowiązkach i większego uzależniania się człowieka od maszyn. Czy tak jest? Warto sprawdzić, wchodząc na stronę:
www.cubo.cc/creepygirl 2)
Dolina niesamowitości dotyka również branży zabezpieczeń technicznych. Niektórzy mogli się o tym przekonać na tegorocznych targach Securex, podczas których dostawcy i producenci rozwiązań prezentowali systemy analizy danych wizyjnych wspomaganych przez sztuczną inteligencję. Przykłady zastosowań algorytmów pracujących z danymi napływającymi w czasie rzeczywistym, a także wyszukiwania obiektów po charakterystycznych cechach (ludzi – po elementach i kolorystyce ubioru, samochodów – po typie, kolorze, marce i modelu) w materiale zarejestrowanym budziły mój niekłamany podziw. Na początku, po wstępnej fascynacji pojawiła się konsternacja. Jej źródłem było pozostawienie sposobu tworzenia reguł alarmowych znanych z analizy kontekstowej (VCA). Zmiana sposobu wprowadzania reguł na bliższy językowi naturalnemu nawet w jego podstawowej formie, np. taki, jaki znamy z wyszukiwarki obrazów Google (np. „czerwony samochód”, „wysoka kobieta”, „człowiek bez kasku” itp.), znacznie ułatwiłaby korzystanie z najnowszych osiągnięć analizy obrazu. Przede wszystkim jednak obniżyłaby dyskomfort polegający na wypełnianiu wielu pól warunkowych. Niektórym producentom już jakiś czas temu udało się zmniejszyć dolinę niesamowitości przez wprowadzanie filtrów w układzie odniesienia. Polega to na tym, że zakres warunków zostaje wprowadzony do algorytmu automatycznie na podstawie wcześniej oznaczonego obiektu (rys. 2). Jest to bardziej naturalny proces dla człowieka aniżeli wypełnianie formularza z niezależnymi od siebie polami. 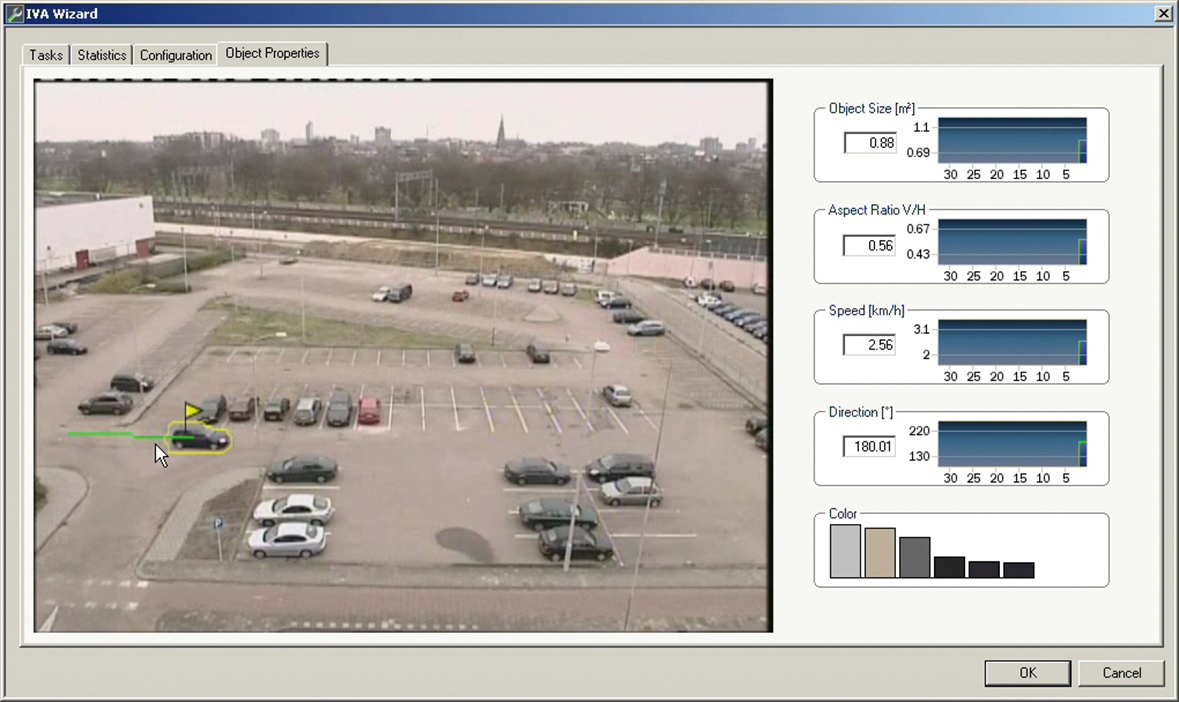

Przy dłuższej zabawie systemem zacząłem wychwytywać nieprawidłowości w rozpoznaniu – wykryty człowiek w okularach, choć na pierwszy rzut oka widać, że ich nie ma, błędne rozpoznanie płci lub wieku czy koloru, złe zaklasyfikowanie obiektu. Dopadające mnie wówczas „mieszane odczucia” były tym większe, im pozytywniej byłem nastawiony na rewolucyjne doznania wynikające z bezpośredniego kontaktu z AI. Z jednej strony obserwowałem wielki postęp w analizie zawartości obrazu, pozwalający zautomatyzować wiele procesów i wspomóc pracowników ochrony lub zdalnego nadzoru w ich codziennej pracy. Z drugiej zaś okazało się, że pomimo innowacyjnego podejścia i wykorzystania sztucznych sieci neuronowych maszyna pozostała maszyną i niezmiennie popełniała podstawowe błędy, których człowiek by się wystrzegł. Tym samym nie jest bliższa w sposobie działania naszemu postrzeganiu i naszej świadomości. Duplex być może potrafi wykonać zadanie umówienia wizyty u fryzjera, ale bez wątpienia będzie miał ogromny kłopot z rozmową przy porannej kawie, obfitującą w wiele wątków, które tylko pozornie nie są ze sobą powiązane. Analiza kontekstowa danych wizyjnych w systemach dozoru wizyjnego obecnie radzi sobie z wykryciem dowolnego obiektu nawet w trudnych warunkach oświetleniowych, ale „wykłada się” w rozpoznaniu człowieka stojącego po kolana w trawie w ciągu dnia, gdy wyposaża się ją w zdolność klasyfikacji.
Oba przytoczone przykłady łączy jeden fakt: algorytmy analizują konkretny obszar związany z danym tematem. Dla Duplexa jest to rezerwacja stolika w restauracji lub terminu w salonie piękności. Dla typowej analizy VCA jest to detekcja naruszenia chronionej strefy przez obiekt o zadanych parametrach. Ponieważ algorytm analizuje dane z wyuczonego obszaru tematycznego (do którego obróbki został zaprogramowany), należy spodziewać się, że reakcje na przychodzące dane będą prawidłowe lub bliskie prawidłowym. Gdy jednak wprowadzimy dane z innego obszaru tematycznego (np. produktowi Google’a zadamy temat zakupu karmy dla kota a analizie obrazu wykrywającej naruszenie strefy oszacowanie liczby ludzi), otrzymamy błędne informacje wynikowe (Duplex będzie prawdopodobnie odpowiadał bez większego sensu, a VCA zapewne poda zerową wartość). Innymi słowy algorytmy działają poprawnie, gdy spełnione zostaną wcześniej ustalone warunki logiczne. W ten sposób działa obecnie większość algorytmów w security – otrzymamy powiadomienie, jeśli zostanie spełnione kryterium dla zdefiniowanego zdarzenia w określonym środowisku.
Praca algorytmu analizy zawartości obrazu jest mierzona w dwóch kategoriach:
- prawdopodobieństwo wykrycia – prezentowane jako procentowy (%) stosunek zdarzeń wykrytych przez system do wymaganej, sumarycznej liczby zdarzeń wymagających wykrycia. Przykładem może być system zliczania osób: w danej jednostce czasu zmierzona liczba przejść w systemie jest porównywana z wynikami zebranymi np. przez osoby zliczające;
- poziom fałszywych alarmów – liczba zdarzeń, które zostały odnotowane w systemie, a które nie były istotne. Liczba fałszywych alarmów jest zawsze postrzegana jako wartość krytyczna. Jedno błędne zdarzenie przypadające na jedną kamerę w ciągu jednego dnia jest jeszcze do zaakceptowania, ale system składający się z 400 kamer będzie alarmował o wykryciu średnio co 4 minuty. W tym przypadku istotne zdarzenia pozostaną niedostrzeżone, a cały system stanie się nieefektywny. Sumaryczną liczbę zgłoszeń można obniżyć, zawężając warunki detekcji, np. obiekt może być dookreślony przez takie dodatkowe parametry, jak jego wielkość, stosunek wysokości do szerokości, kolor lub kierunek przemieszczania się itp.
AI po części rozwiązało kwestię definiowania obiektów przez wprowadzenie klas, np. człowiek-pojazd. Zastosowanie rozwiązań uczenia maszynowego pozwoliło na stworzenie „definicji” obiektu dzięki procesowi wyszukiwania ogólnych wzorców. Algorytm jest zasilany danymi przedstawiającymi ten sam obiekt (lub typ obiektu), ale w różnych pozycjach (np. stojący, leżący), jak również obserwowany pod różnym kątem. Sam proces uczenia może się odbywać w sposób nadzorowany lub nienadzorowany. Uczenie nadzorowane polega na zasileniu systemu danymi wejściowymi i wyjściowymi, który na ich podstawie powinien stworzyć odpowiednie reguły (proces generalizacji) przekładające wejście na wyjście. Po odpowiednim wytrenowaniu system powinien móc prawidłowo przypisać wyjście do obiektu, którego dotychczas nie było na wejściu. Taki system uczenia jest nadal najpopularniejszy w uczeniu maszynowym, choć jest bardzo czasochłonny. Zazwyczaj wiąże się bowiem z udziałem człowieka–operatora, który wspomaga maszynę w procesie uczenia, wprowadzając tysiące przykładów szkoleniowych i ręcznie poprawiając wszelkie powstałe błędy. Uczenie nienadzorowane polega na tym, że systemowi nie podaje się oczekiwanych danych wyjściowych. Zatem on sam musi znaleźć odpowiednią regułę, charakteryzującą wejście i w miarę możliwości zgeneralizować ją. Taki proces wspomagany przez głębokie uczenie znacząco przyspiesza odnalezienie modeli uogólniających – z nim wiąże się największe nadzieje.
Obecne systemy opierające się na modelach statystycznych mają ogromny problem z zaklasyfikowaniem obiektu tylko częściowo widocznego. Osoba wychylająca się zza budynku, przesłonięta przez elementy małej architektury lub stojąca w wysokiej trawie nie pasuje do modelu. Człowiek zdefiniowany jako zbiór punktów określających położenie głównych stawów, aby zostać przypisany do konkretnej kategorii, musi „załadować się” cały. Analiza obrazu wykrywająca naruszenie strefy chronionej, wyposażona w klasyfikację obiektów potrafi skutecznie odfiltrować niechciane naruszenia przez zwierzęta lub nagłą zmianę kontrastu w polu (np. nagłe oświetlenie lub zacienienie). Gdy jednak w obserwowanym obszarze znajduje się roślinność, a człowiek nie jest w pełni widoczny, system odfiltruje i to zdarzenie jako fałszywe. W takim przypadku klasyfikacja zredukuje liczbę fałszywych alarmów, ale obniży też prawdopodobieństwo wykrycia.
Sztuczne sieci neuronowe mają wiele ograniczeń wynikających z ich natury. Podstawowym jest ich statystyczne podejście – duża dokładność wymaga dużego zestawu przykładów do uczenia, a nauczona sieć nie poradzi sobie z efektami, które nie wystąpiły w tych przykładach. Wydaje się zatem, że dużo efektywniejszym sposobem ich wykorzystania do celów analizy zawartości obrazu jest stworzenie rozwiązań informujących o anomaliach w obserwowanej scenie, czyli zdarzeniach, które są nietypowe dla obserwowanego obszaru. Algorytm bez przerwy zasilany strumieniem danych wizyjnych uczy się typowej aktywności w scenie, by w konsekwencji wykryć i oznaczyć nietypowy ruch. Im dłuższy jest okres uczenia i większa powtarzalność zachowań, tym lepszych efektów należy się spodziewać.
Ograniczenia związane z jakością detekcji algorytmów VCA, a także nierozpoznane dotychczas problemy wynikające z wprowadzeniem AI powodują, że przebojem dostają się do branży zabezpieczeń technicznych rozwiązania z innych dziedzin. Dynamiczny rozwój prac nad pojazdami autonomicznymi obfituje w rozwój technologii, które z powodzeniem mogą i są wykorzystywane w branży security. Masowe zastosowanie techniki radarowej FMCW (fala ciągła modulowana częstotliwościowo) w branży samochodowej spowodowało spadek cen tych urządzeń, dzięki czemu stały się one atrakcyjnym rozwiązaniem również jako element elektronicznych zabezpieczeń technicznych. Rośnie również apetyt na LiDAR (technologia podobna do techniki radarowej, wykorzystująca światło zamiast mikrofal), dla którego wielkość rynku w 2015 r. wynosiła 365,5 mln USD, a wg najnowszych prognoz przekroczą 1,1 mld USD do 2023 r. [3]
Zgodnie z oczekiwaniami ekspertów rynku security takie „niewizyjne czujniki” zapewnią uzyskanie widoku wielowymiarowego, dostarczając dane umożliwiające szybszą i dokładniejszą ocenę sytuacji, a co za tym idzie szybszą reakcję, uruchomienie odpowiednich działań oraz minimalizację liczby fałszywych alarmów. Jako przykład można wskazać technologię radarową do wykrywania ruchu, dobrze znane obrazowanie termowizyjne do klasyfikacji, a także detekcję dźwięku. Postęp w rozwoju tej drugiej technologii oznacza pozyskiwanie informacji, których nie zapewnią źródła oparte jedynie na analizie obrazu3). Rozwiązania, które dużo precyzyjniej analizowałyby otoczenie, od dawna znajdują się pod lupą naukowców i działów R&D. Obecnie wyniki tych prac można znaleźć pod hasłami „inteligentnego domu” lub Internetu Rzeczy (IoT), ale cel pozostał niezmienny przez dziesięciolecia – matematyczna analiza bodźców i skuteczniejsze informowanie użytkownika o środowisku, w którym się znajduje. Przez rozmieszczenie wielu połączonych sieciowo czujników w środowisku tworzy się rozproszony system detekcyjny, zwiększający obszar detekcji i poprawiający dokładność odczytów. Analiza danych może wykrywać jeden aspekt (np. detekcję pożaru) lub wiele różnych (np. użycie konkretnego urządzenia w fabryce) [4].
Dokładność odczytów zależy od liczby pozyskanych danych, rozłożenia ich w czasie oraz całego procesu uczenia maszynowego. Rosnące zapotrzebowanie na magazyny tych danych wynika z gromadzenia informacji nieprzetworzonych (tzw. surowych) z różnego typu urządzeń podłączanych w ramach IoT. Zgodnie z przewidywaniami IDC, globalnej firmy badającej rynek technologii informatycznych, należy się spodziewać, że 95% danych do końca 2025 r. będzie pochodzić właśnie z tego kanału [5]. O ile obecnie przyrost danych generują takie urządzenia, jak komputery osobiste, serwery, tablety i smartfony, o tyle w przyszłości będzie zwiększać się liczba urządzeń obserwujących naszą aktywność. Znaczącą ilość danych dostarczą wizyjne systemy zabezpieczeń. Jednak w przypadku kamer nie zakłada się długiego czasu retencji danych wizyjnych, a jedynie metadanych (cyfrowy „opis” obiektu: miejsca zajmowanego przez niego w obrazie, wielkości, koloru, wektora ruchu powiązanych ze znacznikiem czasu itp.) zebranych na ich podstawie.
 Obecnie jesteśmy w okresie przejściowym. Zachłyśnięci AI, IoT, Big Data, mamy duże oczekiwania i rozczarowuje nas nieporadność nowych technologii. Nie mam też wątpliwości, że kolejna generacja elektronicznych systemów zabezpieczeń technicznych będzie czymś więcej niż kojarzone z branżą typowe urządzenia do przechwytywania obrazu. Docelowo będzie to połączenie kamer wstępnie analizujących treści wizyjne, różnego typu czujników i oprogramowania analizującego wszystkie zebrane dane. Nieodległe już rozwiązania security będą nie tylko wykrywać i dokumentować incydenty, lecz również analizować ich przebieg, przedstawiać wnioski i sugerować odpowiednie działania zaradcze4). To będzie moment, gdy przeskoczymy dolinę niesamowitości.
Obecnie jesteśmy w okresie przejściowym. Zachłyśnięci AI, IoT, Big Data, mamy duże oczekiwania i rozczarowuje nas nieporadność nowych technologii. Nie mam też wątpliwości, że kolejna generacja elektronicznych systemów zabezpieczeń technicznych będzie czymś więcej niż kojarzone z branżą typowe urządzenia do przechwytywania obrazu. Docelowo będzie to połączenie kamer wstępnie analizujących treści wizyjne, różnego typu czujników i oprogramowania analizującego wszystkie zebrane dane. Nieodległe już rozwiązania security będą nie tylko wykrywać i dokumentować incydenty, lecz również analizować ich przebieg, przedstawiać wnioski i sugerować odpowiednie działania zaradcze4). To będzie moment, gdy przeskoczymy dolinę niesamowitości.
| Uczenie maszynowe |
| Pogłębione uczenie maszynowe jest specyficznym przetwarzaniem konkretnych danych. Program nie wie, co przetwarza i w jakim celu. Posiada tylko instrukcję, że gdy na wejściu jest x, y albo z, to odpowiedzią powinno być a – jeśli nie, stara się sam oszacować wynik. Metodą prób i błędów dopasowuje swój algorytm działania, chcąc uzyskać odpowiedź. Algorytm zaś przy każdym powtórzeniu dąży do uzyskania jak najmniejszego poziomu błędu (odpowiednio dopasowując wagi relacji w sztucznej sieci neuronowej). Sam proces uczenia wymaga odpowiedniego zasobu danych wejściowych i odpowiednio dużej liczby powtórzeń. |
| Jakość analizy obrazu |
| Na poprawność działania analizy obrazu wpływają czynniki związane z obrazem i przetwarzaniem sygnału wizyjnego: poziom kompresji, rozdzielczość, poklatkowość, kontrast między tłem a obiektem, odwzorowanie barw, poziom wzmocnienia sygnału, prędkość poruszania się obiektu, wielkość obiektu, poziom ruchu w scenie, perspektywa, warunki środowiskowe i aberracje optyczne. Jakość analizy zależy od wielu zmiennych, dlatego jest niezwykle istotne określenie funkcji i zakresu detekcji. |
1) Konglomerat i holding powołany przez Google – właściciel przedsiębiorstw, w których największym jest Google. Alphabet jest również spółką-matką Calico, Google Ventures, Google Capital, Google X i Nest Labs. 2) Wymagane IE oraz wtyczka flash. 3) The 10 technology trends that will shape 2018, Johan Paulsson, Axis Communications, 2018 4) Securitas Annual Report 2017
Literatura
[1] https://www.androidcentral.com/google-io-2018
[2] Jasia Reichardst: Robots: Fact, Fiction, and Prediction, Viking Press, 1978
[3] Global Market Insights, LiDAR Market Size By Application, Competitive Market Share & Forecast, 2016 – 2023, 2016
[4] Gierad Laput, Yang Zhang, Chris Harrison: Synthetic Sensors: Towards General-Purpose Sensing, Human-Computer Interaction Institute, Carnegie Mellon University, 2017
[5] David Reinsel, John Gantz, John Rydning: Data Age 2025: The Evolution of Data to Life-Critical, An IDC White Paper, Sponsored by Seagate, 2017
Jan T. Grusznic
z-ca red. naczelnego „a&s Polska”. Z branżą wizyjnych systemów zabezpieczeń związany od 2004 r. Ma bogate doświadczenie w zakresie projektowania i wdrażania rozwiązań dozoru wizyjnego w aplikacjach o rozproszonej strukturze i skomplikowanej dystrybucji sygnałów. Ceniony diagnosta zintegrowanych systemów wspomagających bezpieczeństwo.

