









Zarządzanie danymi i wykorzystanie analityki. Cz. 2

Dane i analityka (D&A) odnoszą się do sposobów zarządzania informacjami w celu obsługi wszystkich możliwych zastosowań dla danych i wyników ich analizy podejmowania lepszych decyzji, optymalizacji procesów biznesowych, jak i odkrywania nowych zagrożeń biznesowych, wyzwań i możliwości.
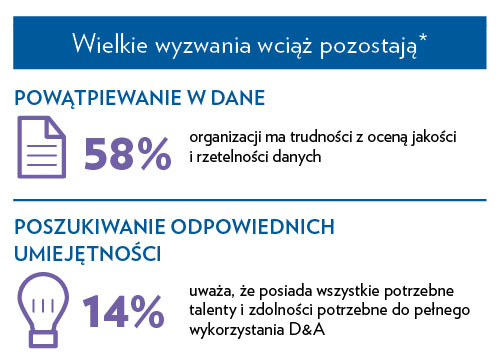
Przyszłość technologii danych i analityki wg Gartnera1
Platformy analizy danych również m.in. z dziedziny wywiadu przemysłowego, tzw. Business Intelligence, rozwijają potencjał tkwiący w nauce o danych, tworząc z kolei nowe rozwiązania i nowe platformy wykorzystujące D&A, które wspomagają proces decyzyjny. Dostawcy usług w chmurze, gdzie uruchamianych jest coraz więcej narzędzi i platform, wprowadzają dodatkowy poziom kompleksowości (w rozumieniu wszechstronności – przyp. red.) rozwiązania.
Tradycyjne platformy na rynkach danych, analizy i sztucznej inteligencji z trudem radzą sobie z obsługą rosnącej liczby przypadków użycia i przetwarzania danych, dlatego organizacje muszą równoważyć wysoki całkowity koszt posiadania istniejących rozwiązań lokalnych z potrzebą zwiększenia zasobów i nowymi możliwościami, takimi jak zapytania w języku naturalnym, eksploracja tekstu oraz analiza danych semistrukturalnych2 i nieustrukturyzowanych3.
Przyszłość D&A wymaga zatem od organizacji inwestycji w tzw. komponowalne4 architektury zarządzania danymi i analityki w celu wsparcia zaawansowanej analityki.
Nowoczesne systemy i technologie D&A będą prawdopodobnie obejmować następujące elementy:
Systemy zarządzania danymi:
Zarządzanie danymi podstawowymi (Master Data Management – MDM) jest wspieraną przez technologię dyscypliną biznesową, w której funkcje biznesowe i informatyczne współpracują ze sobą w celu zapewnienia jednolitości, dokładności, zarządzania, spójności semantycznej i odpowiedzialności za oficjalne współdzielone zasoby danych podstawowych przedsiębiorstwa.
Węzły danych (data hubs) skupiają się na udostępnianiu danych i zarządzaniu nimi. Producenci i odbiorcy danych łączą się ze sobą za ich pośrednictwem, a kontrola zarządzania i wspólne modele są stosowane w celu umożliwienia efektywnego udostępniania danych. MDM to węzeł skupiający się wyłącznie na danych podstawowych. Katalogi danych w coraz większym stopniu wkraczają w przestrzeń zarządzania, przez co i w efekcie zaczynają stawać się węzłami danych (i analityki).
Centra danych (data centers) mieszczą fizycznie serwery (w przeciwieństwie do hurtowni, które są strukturami danych umieszczonymi na serwerach lub w chmurze), a ich przyszłość zależy od stopnia, w jakim obciążenie może być przeniesione do chmury. Decyzje o migracji muszą być oparte na korzyściach biznesowych ekonomicznych z tego płynących.
Hurtownie danych (data warehouses) stanowią punkt końcowy dla gromadzenia danych transakcyjnych, szczegółowych (a czasami innych typów). Wspierają przewidywalne analizy dla danych, których wartość jest dobrze ugruntowana – to znaczy dobrze znane, predefiniowane i powtarzalne analizy, które są skalowalne dla wielu użytkowników w przedsiębiorstwie.
Jeziora danych (data lakes) gromadzą nieprzetworzone dane (w ich natywnej postaci, z ograniczoną transformacją i zapewnieniem jakości oraz wewnętrznym zarządzaniem) oraz pozwalają użytkownikom na ich eksplorację i analizę w wysoce interaktywny sposób. Jeziora danych nie zastępują hurtowni danych ani innych systemów ewidencji, ale raczej je uzupełniają, przechowując nieprzetworzone dane, które mogą mieć dużą wartość.

kpmg.com/data
Data fabric
Data fabric to nowa koncepcja zarządzania danymi, która umożliwia rozszerzoną integrację i współdzielenie danych z różnorodnych źródeł danych. To coraz popularniejsze rozwiązanie, pozwalające na uproszczenie infrastruktury integracji danych organizacji i stworzenie skalowalnej architektury.
Po powszechnym wdrożeniu data fabric mogą w znacznym stopniu wyeliminować ręczne zadania związane z integracją danych oraz rozszerzyć (a niekiedy całkowicie zautomatyzować) projektowanie i dostarczanie integracji danych. To wciąż jednak nowa koncepcja, a żaden z dostawców nie dostarcza obecnie w sposób zintegrowany wszystkich kompletnych elementów, które są niezbędne do połączenia struktury danych. Ostatecznie to organizacje muszą zdecydować, czy chcą utworzyć własną sieć data fabric, korzystając z najnowszych możliwości obejmujących wymienione technologie oraz inne, np. aktywne zarządzanie metadanymi.
Data fabric składa się również z mieszanki dojrzałych i mniej dojrzałych komponentów technologicznych, dlatego organizacje muszą ostrożnie je łączyć i dopasowywać w miarę indywidualnego rozwoju rozwiązania.
kpmg.com/data
Dane i analityka w chmurze
Tradycyjne platformy D&A muszą radzić sobie z coraz bardziej skomplikowaną analizą, a całkowity koszt posiadania rozwiązań lokalnych stale rośnie ze względu na ich złożoność, coraz większą zasobożerność (większe zużycie zasobów urządzeń, serwerów, dysków itp. – przyp. red.) i koszty utrzymania rozwiązania. Z kolei dane i analiza w chmurze oferują większą wartość i możliwości dzięki nowym usługom, prostocie i sprawności w zakresie modernizacji danych, a także wymaganych nowych rodzajów analiz (takich jak analiza strumieniowa), wyspecjalizowanych magazynów danych i przyjaźniejszych dla użytkownika narzędzi do obsługi kompleksowego wdrożenia.
Wdrożenie w chmurze – hybrydowej, wielochmurowej lub międzychmurowej – musi uwzględniać wiele elementów D&A, w tym pobieranie danych, integrację danych, modelowanie danych, optymalizację danych, bezpieczeństwo danych, jakość danych, zarządzanie danymi, raportowanie zarządcze, naukę o danych i uczenie maszynowe.

kpmg.com/data
Big data czy small data? A może wide data?
Termin „big data” jest używany od dziesięcioleci do opisywania danych charakteryzujących się dużą objętością, dużą szybkością i dużą różnorodnością oraz innymi ekstremalnymi warunkami. Era big data jest jednak dla firm uosobieniem zagrożeń i możliwości, a konkretnie tego, że eksplozja ruchu danych (zwłaszcza wraz ze wzrostem korzystania z Internetu i mocy obliczeniowej) stanowi bogate źródło wiedzy pozwalającej na podejmowanie lepszych decyzji, ale jednocześnie stwarza wyzwania dla organizacji w zakresie przechowywania, zarządzania i analizowania ogromnej ilości danych.
Większość organizacji znalazła sposoby pozyskiwania informacji biznesowych z big data, ale wiele z nich ma problemy z zarządzaniem i analizowaniem zróżnicowanego i szerokiego zestawu treści (w tym materiałów audio, wideo i obrazów) na dużą skalę, szczególnie w sytuacji, gdy liczba źródeł danych rośnie i zmienia się, a zapotrzebowanie na informacje jest w coraz większym stopniu zaspokajane przez zaawansowaną analizę.

kpmg.com/data
Postępowe organizacje nie stosują już rozróżnienia między zarządzaniem, administrowaniem i wyciąganiem wniosków z niewielkich czy dużych zbiorów danych. Obecnie to wszystko są po prostu dane. Zamiast tego agresywnie dążą do wykorzystania nowych rodzajów danych i analiz oraz znalezienia zależności w kombinacjach różnych danych w celu poprawy decyzji biznesowych, procesów i wyników ekonomicznych.
Globalna pandemia i inne zakłócenia w działalności gospodarczej również przyspieszyły potrzebę wykorzystania większej liczby różnych danych w szerokim zakresie przypadków (zwłaszcza że historycznie duże zbiory danych okazały się mniej istotne jako podstawa przyszłych decyzji). Obawy związane z pozyskiwaniem danych, ich jakością, stronniczością i ochroną prywatności również wpłynęły na gromadzenie big data, w wyniku czego pojawiły się nowe podejścia znane jako „small data” i „wide data”.
Podejście oparte na wide data umożliwia analizę i synergię różnych – małych i dużych – źródeł danych, zarówno wysoko zorganizowanych danych ilościowych (ustrukturyzowanych), jak i danych jakościowych (nieustrukturyzowanych). Podejście oparte na small data wykorzystuje szereg technik analitycznych do generowania użytecznych wniosków, ale czyni to przy użyciu mniejszej ilości danych.
W firmie Gartner używany jest obecnie termin X-analytics, aby zbiorczo opisać małe, szerokie i duże dane (w rzeczywistości wszystkie rodzaje danych). Należy się jednak spodziewać, że do 2025 roku 70% organizacji będzie zmuszonych do przesunięcia punktu ciężkości z big data na small data i wide data, aby efektywniej wykorzystać dostępne dane – albo poprzez zmniejszenie wymaganej objętości, albo wydobywając większą wartość z nieustrukturyzowanych, różnorodnych źródeł danych.

kpmg.com/data
Ta i inne prognozy dotyczące ewolucji analityki danych zawierają ważne założenia planowania strategicznego, które pozwolą na poprawę wizji i realizacji zadań z zakresu D&A.
Uzyskiwanie wartości dodanej z inicjatyw D&A wymaga trzech komponentów: użytecznych obserwacji, silnych procesów zarządzania zmianą oraz wsparcia ze strony kierownictwa. Jednak przede wszystkim wymaga od organizacji fundamentalnie innego podejścia do D&A, które zaczyna się od zrozumienia tego, co biznes chce osiągnąć, a następnie dostosowania do tego narzędzi D&A, możliwości i posiadanych danych, tak aby odpowiednio mocno wspierały cele biznesowe.
Zobacz pierwszą część artykułu:
Zarządzanie danymi i wykorzystanie analityki. Cz. 1
1 https://www.gartner.com/en/topics/data-and-analytics
2 Dane semistrukturalne to nowy model danych oparty na drzewach. Reprezentacja danych jest bardziej elastyczna niż w relacyjnych bazach danych. Schemat bazy jest często wpisany bezpośrednio w dane, można to określić jako dane ,,samo-opisujące się”. Przykładem mogą być pliki XML. Model semistrukturalny przydaje się też przy integracji informacji ze źródeł o różnej strukturze.
3 Dane nieustrukturyzowane to informacje, które nie mają wstępnie zdefiniowanego modelu danych lub nie są zorganizowane we wstępnie zdefiniowany sposób. Informacje nieustrukturyzowane zazwyczaj zawierają dużo tekstu, ale mogą też zawierać dane, np. daty, liczby i fakty. Skutkuje to nieprawidłowościami i niejasnościami, które utrudniają zrozumienie przy użyciu tradycyjnych programów.
4 Komponowalna infrastruktura to koncepcja architektury serwera centrum danych, w której różne zasoby przetwarzania, pamięci masowej i akceleratora nie są związane z fizyczną lokalizacją, a zarządzanie nimi odbywa się za pośrednictwem interfejsu w oparciu o oprogramowanie. Pula zasobów w ramach komponowalnej infrastruktury jest tworzona automatycznie niemal w czasie rzeczywistym, dostosowując je do potrzeb wszystkich aplikacji lub obciążeń roboczych działających w przedsiębiorstwie.

