









Sztuka łączenia, czyli o fuzji obrazów

Jakub Sobek
W najbliższych latach coraz częściej będziemy spotykali zarówno zastosowania fuzji danych z różnych sensorów, jak i fuzji wizyjnej. Warto eksperymentować, łączyć i poszukiwać „nowych smaków”…
Dobrego kucharza poznaje się nie po tym, że potrafi przygotować smaczne danie z wyjątkowych produktów. Prawdziwego kunsztu kulinarnego wymaga przygotowanie smacznego dania z podstawowych jedynie produktów. Smaczne danie łączy smaki poszczególnych składników w spójną, czasem zaskakującą całość. Najczęściej właśnie dlatego lubimy chodzić do restauracji.
W filharmonii spodziewamy się wzruszających połączeń nie tyle smaków, ile dźwięków. Piękny koncert łączy grę wielu instrumentów i tylko ich prawidłowe współbrzmienie tworzy wyjątkowość danego dzieła. Gdyby każdy instrument kolejno odgrywał swoją partię, efekt byłby rozczarowujący. Zarówno zmysł smaku, jak i słuchu lubią umiejętne połączenia. Podobnie wzrok – sztuka może być jednym z takich przykładów.
W branży zabezpieczeń technicznych takie połączenia także można spotkać. Należy do nich m.in. fuzja obrazów. Rzadko jeszcze spotykana, dla wielu niezrozumiała, zyskuje na popularności. Tym umiejętnym połączeniom warto przyjrzeć się bliżej.
Co można ze sobą połączyć?
Fuzja oznacza łączenie wielu rzeczy w całość. W odniesieniu do systemów wizyjnych to np. połączenie dwóch lub większej liczby pojedynczych obrazów, a nawet sekwencji wizyjnych w jeden obraz wynikowy. Można ze sobą łączyć nie tylko media pochodzące ze źródeł tego samego typu, można np. połączyć obrazy z danymi uzyskanymi z urządzenia Lidar (skaner laserowy) w celu utworzenia przestrzennych map otoczenia.
Coraz popularniejsze roboty i autonomiczne samochody, które za chwilę wkroczą w naszą rzeczywistość, właśnie z takiej fuzji korzystają. W wielu koncepcjach jest ona niejednokrotnie nawet bardziej złożona – łączą się ze sobą obrazy z kamery, dane ze skanera Lidar, z czujników ultradźwiękowych oraz radarów krótkiego zasięgu. Takie heterogeniczne rozwiązanie tworzy mapę otoczenia, łącząc różne zarejestrowane atrybuty środowiska. Dzięki temu pojazd widzi znaki zarówno poziome, jak i pionowe, może oceniać prędkość poruszających się obiektów i odległość od nich oraz prowadzić złożoną analizę ruchu wszystkich rejestrowanych obiektów.
W klasycznej fotografii przykładem fuzji wizyjnej jest metoda HDR (High Dynamic Range – wysoki zakres dynamiki). Polega ona na połączeniu dwóch lub kilku zdjęć wykonanych z różnym czasem ekspozycji w jedno zdjęcie o znacznie szerszym zakresie kolorów (skali szarości) i poziomów jasności niż każda ramka z osobna. Takie zdjęcie ma dla wielu osób dodatkowe walory estetyczne i artystyczne. Istnieje wiele metod i technologii HDR, efekt zastosowania HDR dla tych samych zdjęć będzie inny – może zależeć od tego, czy użyjemy obrazów już skompresowanych, np. JPEG, czy obrazów typu RAW. Często obraz uzyskany w technologii HDR ma na tyle dużą rozpiętość tonalną, że nie można go prawidłowo wyświetlić na monitorze lub wydrukować. Konieczne jest wówczas przeskalowanie otrzymanej dynamiki, często nazywane mapowaniem tonalnym. Przykładowo na rys. 1 przedstawiono połączenie zdjęć wykonanych z różnym czasem naświetlania oraz końcowy efekt w postaci zdjęcia HDR.
Kamery dozorowe często mają funkcję WDR (Wide Dynamic Range – szeroki zakres dynamiki). W zależności od producenta lub modelu kamery efekt ten może być uzyskiwany na różne sposoby. Pierwsza z metod polega na rejestracji obrazu o większej głębi tonalnej niż ten, który rzeczywiście może być wyświetlony. Następnie przeskalowuje się cały zakres, zwracając szczególną uwagę na miejsca prześwietlone i niedoświetlone. Druga metoda jest taka sama jak stosowana w fotografii metoda HDR (czasem tych nazw używa się zamiennie). Polega na tym, że kamera w czasie rzeczywistym wykonuje dwie ekspozycje obrazu i następnie składa je ze sobą. Również w tym przypadku można mówić o fuzji wizyjnej. Funkcja WDR wymaga procesorów sygnałowych o większej mocy obliczeniowej. Szybko poruszające się obiekty mogą być w obrazie wynikowym rozmazane, co jest efektem przemieszczenia się obiektu między pierwszą a drugą klatką. W ostatnich latach nastąpił rozwój technologii WDR, które stosują dodatkowo algorytmy redukcji szumów oraz wzmocnienia obrazu. Wybierając kamery z funkcją WDR, należy pamiętać, że mogą one działać w zupełnie inny sposób, dając obraz znacznie różniący się jakością, mimo że parametry fizyczne kamer mogą być do siebie bardzo zbliżone.
Fuzja wizyjno-termowizyjna
Jedną z odmian fuzji wizyjnej, która coraz częściej zaczyna pojawiać się w systemach telewizji dozorowej, jest łączenie obrazów światła widzialnego z obrazami termowizyjnymi. Dzieje się tak m.in. dlatego, że upowszechniły się przetworniki termowizyjne o niskich rozdzielczościach, np. 80 x 60 pikseli lub 160 x 120 pikseli. Uzyskiwane z nich obrazy mają niską szczegółowość. Aby nadać im większą szczegółowość, producenci decydują się na fuzję wizyjną. Użytkownik ma wrażenie pracy z kamerą termowizyjną o znacznie wyższej rozdzielczości niż jest w rzeczywistości. Taka kamera termowizyjna potrzebuje jednak światła widzialnego, aby generować szczegółowy obraz, co tak naprawdę jest zaprzeczeniem idei termowizyjnej. Dla wielu celów takie ograniczenie nie stanowi większej przeszkody, ale to pewna słabość tych rozwiązań, którą trzeba brać pod uwagę podczas planowania pracy systemu i przy ocenie ryzyka.
W przypadku termowizji obrazy można łączyć na wiele sposobów. Ich wynik czasem zachwyca, czasem jest daleki od ideału. To, z jakiej metody korzysta producent danej kamery, najczęściej wprost zależy od jej mocy obliczeniowej. Trzeba pamiętać, że procesor sygnałowy musi w czasie rzeczywistym połączyć ze sobą dwa strumienie obrazu – z przetwornika światła widzialnego i przetwornika termowizyjnego. Obraz tradycyjny ma zazwyczaj rozdzielczość full HD lub większą, termowizyjny natomiast znacznie niższą, np. 80 x 60, 320 x 240 lub 640 x 480 pikseli. Pierwszym krokiem, jaki należy wykonać, jest przeskalowanie tych obrazów, by ich rozmiary były takie same. Najczęściej powiększa się obraz termowizyjny, stosując jego interpolację. Może się też zdarzyć, że proporcje obrazu będą inne, np. obraz wizyjny w formacie 16:9, termowizyjny – w formacie 4:3. W takim przypadku nałożenie i fuzja obrazów mogą być wykonane tylko na ich obszarze wspólnym. W celu zaprezentowania, jak działa taka fuzja, posłużę się dwoma zdjęciami wejściowymi z kamery światła widzialnego i kamery termowizyjnej (rys. 2).

Przenikanie obrazów
Jedną z najprostszych metod wykonania fuzji obrazu wizyjnego i obrazu termowizyjnego jest nałożenie ich na siebie, a następnie procentowe ustawienie przenikalności obrazu znajdującego się na wierzchu. Często taką metodę stosuje się także do porównania dwóch obrazów niewiele się różniących między sobą. Nałożenie obrazów i ustawienie ich przenikania jest często wygodniejsze niż porównywanie obrazów ustawionych obok siebie. Często z funkcji „przeźroczystości” obrazów korzystają graficy komputerowi, tworząc np. kolaże w programach graficznych. Większość najpopularniejszych programów umożliwia takie operacje.
Najczęściej w dostępnych na rynku budżetowych kamerach termowizyjnych właśnie ta metoda fuzji jest stosowana. Obraz wizyjny stanowi podkład, na niego nakłada się z pewną przeźroczystością obraz termowizyjny. W niektórych aplikacjach metoda ta się sprawdza, jednak zazwyczaj otrzymany obraz wyjściowy nie ma zbyt wysokiej jakości. W tej metodzie istotny jest dobór właściwej palety barwnej dla obrazu termowizyjnego, aby obserwowana scena była czytelna, a kolory najbardziej jaskrawe podkreślały np. najcieplejsze jej elementy.

Spotyka się również nieco bardziej złożone metody ustawiania przenikalności, polegające na definiowaniu tego parametru osobno dla każdego piksela. W ten sposób całkowitą przenikalność można ustawić dla obszarów z dolnego zakresu histogramu, co może reprezentować chłodniejsze obiekty, a zerową przepuszczalność dla górnych zakresów histogramu – obiekty cieplejsze. Dzięki temu na obraz wizyjny nakładane są tylko najcieplejsze obiekty w danej scenie. Odnosi się wówczas wrażenie, że obraz termowizyjny jest „progowany” temperaturowo.
Dodawanie krawędzi
Nieco bardziej złożoną metodą tworzenia obrazu multimodalnego jest wykorzystanie obrazu światła widzialnego i dołożenie do niego jedynie krawędzi obiektów, które pochodzą z obrazu termowizyjnego. Tutaj złożoność obliczeniowa jest zazwyczaj nieco większa. Trzeba bowiem pamiętać, że filtracja obrazu jest operacją kontekstową, w której wartość każdego piksela obrazu wyjściowego wyznacza się jako kombinację pikseli z sąsiedztwa. Istnieje wiele algorytmów detekcji krawędzi – od korzystających z prostego filtrowania obrazu, poprzez coraz bardziej złożone i ciągle doskonalone.
Jedną z podstawowych metod detekcji krawędzi jest filtrowanie obrazu tzw. Krzyżem Robertsa. To operator łatwy w implementacji i nie wymaga dużej złożoności obliczeniowej, dlatego jest często stosowany w prostych aplikacjach. Aby obliczyć wartość każdego piksela na obrazie, wystarczy analiza tylko czterech pikseli, przy czym obliczenia są wykonywane tylko za pomocą operacji dodawania i odejmowania. Nie jest też wymagana dodatkowa parametryzacja tych obliczeń. Liczone są różnice luminancji pikseli położonych koło siebie po przekątnych, a następnie dodawane ich wartości bezwzględne. W ten sposób filtr wykrywa obszary o wysokiej częstotliwości, co często odpowiada rzeczywistym krawędziom obiektów. Najczęściej dane wejściowe dla takich filtrów stanowi obraz w skali szarości. Główną wadą tego operatora jest jego duża wrażliwość na szumy w obrazie i niezbyt skuteczna detekcja krawędzi wtedy, gdy są niewyraźne i nieostre na obrazie wejściowym.
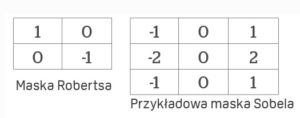 Lepsze rezultaty można uzyskać za pomocą dwuwymiarowej maski Sobela o wielkości 3 x 3. Jest ona szczególnie skuteczna przy detekcji krawędzi pionowych i poziomych. Z powodu większej maski złożoność obliczeniowa tego algorytmu jest większa, jednak jest on operatorem znacznie mniej wrażliwym na zaszumienie obrazu, generuje także znacznie wyższe wartości wyjściowe dla podobnych krawędzi obrazu w porównaniu z metodą Robertsa.
Lepsze rezultaty można uzyskać za pomocą dwuwymiarowej maski Sobela o wielkości 3 x 3. Jest ona szczególnie skuteczna przy detekcji krawędzi pionowych i poziomych. Z powodu większej maski złożoność obliczeniowa tego algorytmu jest większa, jednak jest on operatorem znacznie mniej wrażliwym na zaszumienie obrazu, generuje także znacznie wyższe wartości wyjściowe dla podobnych krawędzi obrazu w porównaniu z metodą Robertsa.
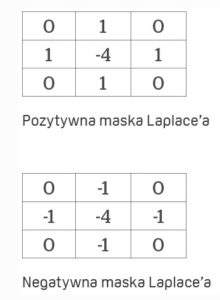
Trzecią metodą wartą uwagi jest różniczkowy operator Laplace’a. Główna różnica między Laplasjanem a innymi operatorami, takimi jak Robertsa czy Sobela, polega na tym, że są to maski pochodne pierwszego rzędu, a Laplasjan jest maską pochodną drugiego rzędu. Ponadto Laplasjan nie pomaga w wyszukiwaniu pionowych i poziomych krawędzi, a wyznacza zewnętrzne i wewnętrzne krawędzie obiektów. Od tego, które z tych krawędzi zostaną wykryte, zależy, czy zastosowana maska będzie negatywna, czy pozytywna – środkowe elementy maski mają znak dodatni lub ujemy. Jest to zatem filtr, który gładkim zmianom jasności obrazu nadaje wartości bliskie zeru, a silnie wzmacnia nagłe zmiany jasności obrazu związane z krawędziami i brzegami obiektów obrazu.
 W zależności od użytych masek każdy obraz wyjściowy wygląda nieco inaczej, inny jest też efekt końcowy polegający na fuzji obrazu wizyjnego z obrazem termowizyjnym po zastosowaniu jednego z operatorów różniczkujących.
W zależności od użytych masek każdy obraz wyjściowy wygląda nieco inaczej, inny jest też efekt końcowy polegający na fuzji obrazu wizyjnego z obrazem termowizyjnym po zastosowaniu jednego z operatorów różniczkujących.



Dekompozycja i łączenie
Kolejny sposób tworzenia obrazów wielomodalnych jest oparty na tzw. dekompozycji dwóch obrazów, a następnie wykonaniu operacji odwrotnej – ich połączenia. Dekompozycję obrazu można wykonać metodą DWT (Discrete Wavelet Transform – dyskretna transformacja falkowa). Ma ona szerokie zastosowanie zarówno w przetwarzaniu, jak i kompresji obrazów. Opublikowany przez komitet JPEG standard kodowania obrazu JPEG 2000 opiera się właśnie na DWT. Dekompozycja DWT każdego z obrazów może być wykonywana wielokrotnie. Każdy obraz (sygnał) wejściowy poddawany takiej dekompozycji jest dzielony na dwa odrębne obrazy zawierające po połowie próbek. Możliwe jest także odtworzenie bezstratne obrazu wejściowego. Każdy zdekomponowany obraz można poddać kolejny raz transformacji DWT. Metodę tę w przetwarzaniu obrazów często wykorzystuje się do redukcji szumów czy filtracji obrazu.
Dekompozycja dwóch obrazów, a także wszystkie wcześniej opisane metody (przenikanie obrazów, detekcja krawędzi za pomocą różnych operatorów) mogą zostać wykonane także w tym środowisku matlab.
Proces łączenia obrazów rozpoczyna się od wczytania obrazów o tej samej wielkości. Gdy różnią się wielkością, są przeskalowywane. Następnie jest wykonywana dekompozycja falkowa z wykorzystaniem konkretnego rodzaju falki. W tym przykładzie zastosowano falkę Daubechiesa. Tak zdekomponowane obrazy można ponownie połączyć. Zastosowana w tym przykładzie fuzja obrazu wymaga maksymalnej selekcji, porównuje się współczynniki DWT obu obrazów i zawsze wybiera współczynnik maksymalny, jedynie dla pasma niskiego liczy się średnią z obu współczynników. Po takim zespoleniu niskich i wysokich pasm dokonuje się rekonstrukcji obrazu za pomocą szybkiej dyskretnej transformacji odwróconej. W ten sposób obraz wynikowy jest kolejną odmianą multimodalnego obrazu z kamery światła widzialnego i kamery termowizyjnej.

Podsumowanie
Z kilku podstawowych produktów można przygotować wiele różnych dań. Dwa wielomodalne obrazy także można łączyć na wiele sposobów, a efekty mogą być różne.
Istotne jest, aby zrozumieć sposób działania fuzji i wiedzieć, jakie daje możliwości, by lepiej ją wykorzystywać w realnych aplikacjach. Ułatwi to podjęcie właściwej decyzji, czy w konkretnym zastosowaniu obraz prezentowany w takiej formie będzie użyteczny. Obraz wielomodalny nie tylko musi być obserwowany przez operatora systemu monitoringu, może też być obrazem wejściowym dla systemów analizy wizji.
Warto pamiętać, że kiedy kolejny producent oferuje kamerę łączącą obraz światła widzialnego z obrazem termowizyjnym, powinniśmy bliżej przyjrzeć się temu, jak taka fuzja jest realizowana. Same hasła marketingowe nie wystarczą, by móc podjąć właściwą decyzję – często tak naprawdę mają tylko zamaskować niską rozdzielczość oferowanej kamery.
Literatura [1] Varuna De Silva, Jamie Roche and Ahmet Kondoz: Robust Fusion of LiDAR and Wide-Angle Camera Data for Autonomous Mobile Robots, Institute for Digital Technologies, Loughborough University, London 2018 [2] Rafał K. Mantiuk, Karol Myszkowski and Hans-Peter Seidel: High Dynamic Range Imaging, Wiley Encyclopedia of Electrical and Electronics Engineering, 2016 [3] Dipalee Gupta, Siddhartha Choubey: Discrete Wavelet Transform for Image Processing, International Journal of Emerging Technology and Advanced Engineering, 2015 [4] Alexander Toet: TNO Image Fusion Dataset, Netherlands Organisation for Applied Scientific Research, 2014 [5] Andrzej Materka, Paweł Strumiłło: Wstęp do komputerowej analizy obrazów, Politechnika Łódzka, Instytut Elektroniki, 2009 [6] http://homepages.inf.ed.ac.uk/rbf/HIPR2/featops.htm [7] https://www.tutorialspoint.com/dip [8] https://www.mathworks.com/matlabcentral/fileexchange/56494-image-fusion-based-wavelet-transform
Jakub Sobek
Absolwent Politechniki Poznańskiej na Wydziale Robotyki i Automatyki, specjalność Systemy wizyjne i multimedialne. Po studiach rozpoczął pracę w firmie Linc Polska na stanowisku trenera technicznego. W 2012 r. zdał egzamin trenera technicznego MOBOTIX, do dziś jest jedynym certyfikowanym trenerem MOBOTIX w Polsce. Posiada także certyfikat trenera rozwiązań FLIR Security Products. Od roku 2015 jest pracownikiem dydaktycznym oraz doradcą zarządu PISA.

